\n",
"\n",
"\n",
"\n",
"\n",
"## The `hops` python module\n",
"\n",
"`hops` is a helper library for Hops that facilitates development by hiding the complexity of running applications and iteracting with services.\n",
"\n",
"Have a feature request or encountered an issue? Please let us know on github.\n",
"\n",
"### Using the `experiment` module\n",
"\n",
"To be able to run your Machine Learning code in Hopsworks, the code for the whole program needs to be provided and put inside a wrapper function. Everything, from importing libraries to reading data and defining the model and running the program needs to be put inside a wrapper function.\n",
"\n",
"The `experiment` module provides an api to Python programs such as TensorFlow, Keras and PyTorch on a Hopsworks on any number of machines and GPUs.\n",
"\n",
"An Experiment could be a single Python program, which we refer to as an **Experiment**. \n",
"\n",
"Grid search or genetic hyperparameter optimization such as differential evolution which runs several Experiments in parallel, which we refer to as **Parallel Experiment**. \n",
"\n",
"ParameterServerStrategy, CollectiveAllReduceStrategy and MultiworkerMirroredStrategy making multi-machine/multi-gpu training as simple as invoking a function for orchestration. This mode is referred to as **Distributed Training**.\n",
"\n",
"### Using the `tensorboard` module\n",
"The `tensorboard` module allow us to get the log directory for summaries and checkpoints to be written to the TensorBoard we will see in a bit. The only function that we currently need to call is `tensorboard.logdir()`, which returns the path to the TensorBoard log directory. Furthermore, the content of this directory will be put in as a Dataset in your project's Experiments folder.\n",
"\n",
"The directory could in practice be used to store other data that should be accessible after the experiment is finished.\n",
"```python\n",
"# Use this module to get the TensorBoard logdir\n",
"from hops import tensorboard\n",
"tensorboard_logdir = tensorboard.logdir()\n",
"```\n",
"\n",
"### Using the `hdfs` module\n",
"The `hdfs` module provides a method to get the path in HopsFS where your data is stored, namely by calling `hdfs.project_path()`. The path resolves to the root path for your project, which is the view that you see when you click `Data Sets` in HopsWorks. To point where your actual data resides in the project you to append the full path from there to your Dataset. For example if you create a mnist folder in your Resources Dataset, the path to the mnist data would be `hdfs.project_path() + 'Resources/mnist'`\n",
"\n",
"```python\n",
"# Use this module to get the path to your project in HopsFS, then append the path to your Dataset in your project\n",
"from hops import hdfs\n",
"project_path = hdfs.project_path()\n",
"```\n",
"\n",
"```python\n",
"# Downloading the mnist dataset to the current working directory\n",
"from hops import hdfs\n",
"mnist_hdfs_path = hdfs.project_path() + \"Resources/mnist\"\n",
"local_mnist_path = hdfs.copy_to_local(mnist_hdfs_path)\n",
"```\n",
"\n",
"### Documentation\n",
"See the following links to learn more about running experiments in Hopsworks\n",
"\n",
"- Learn more about experiments\n",
" \n",
"- Building End-To-End pipelines\n",
" \n",
"- Give us a star, create an issue or a feature request on Hopsworks github\n",
"\n",
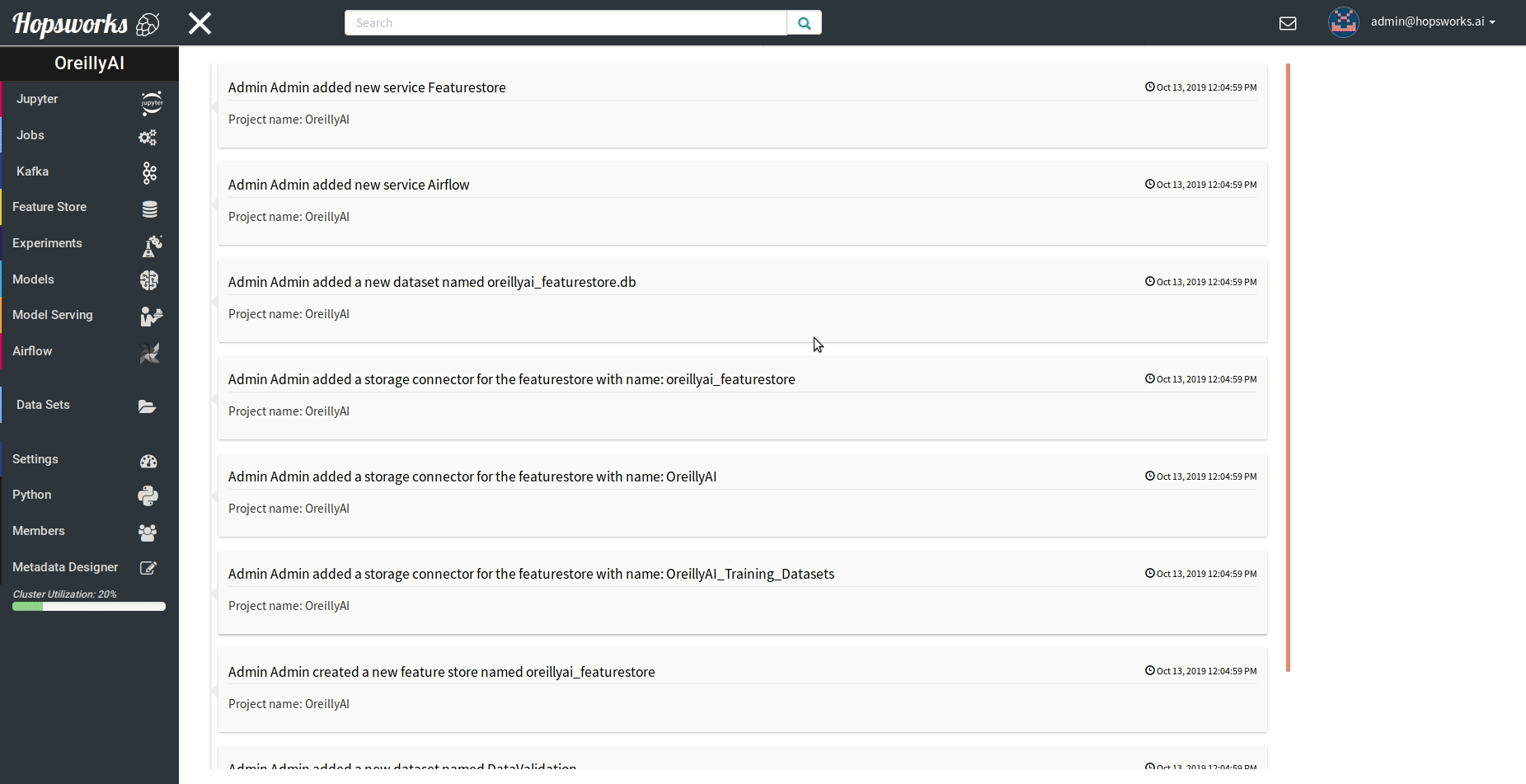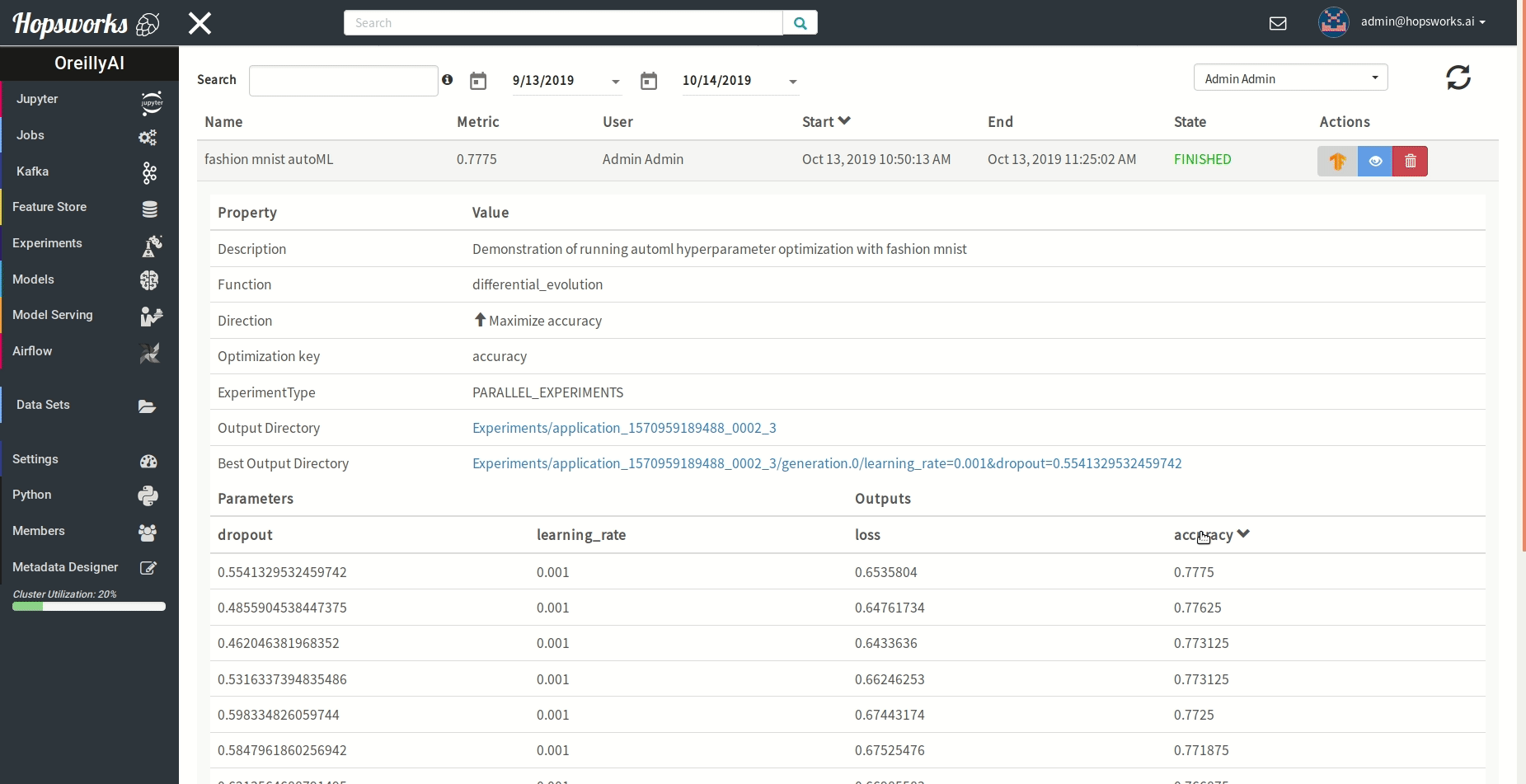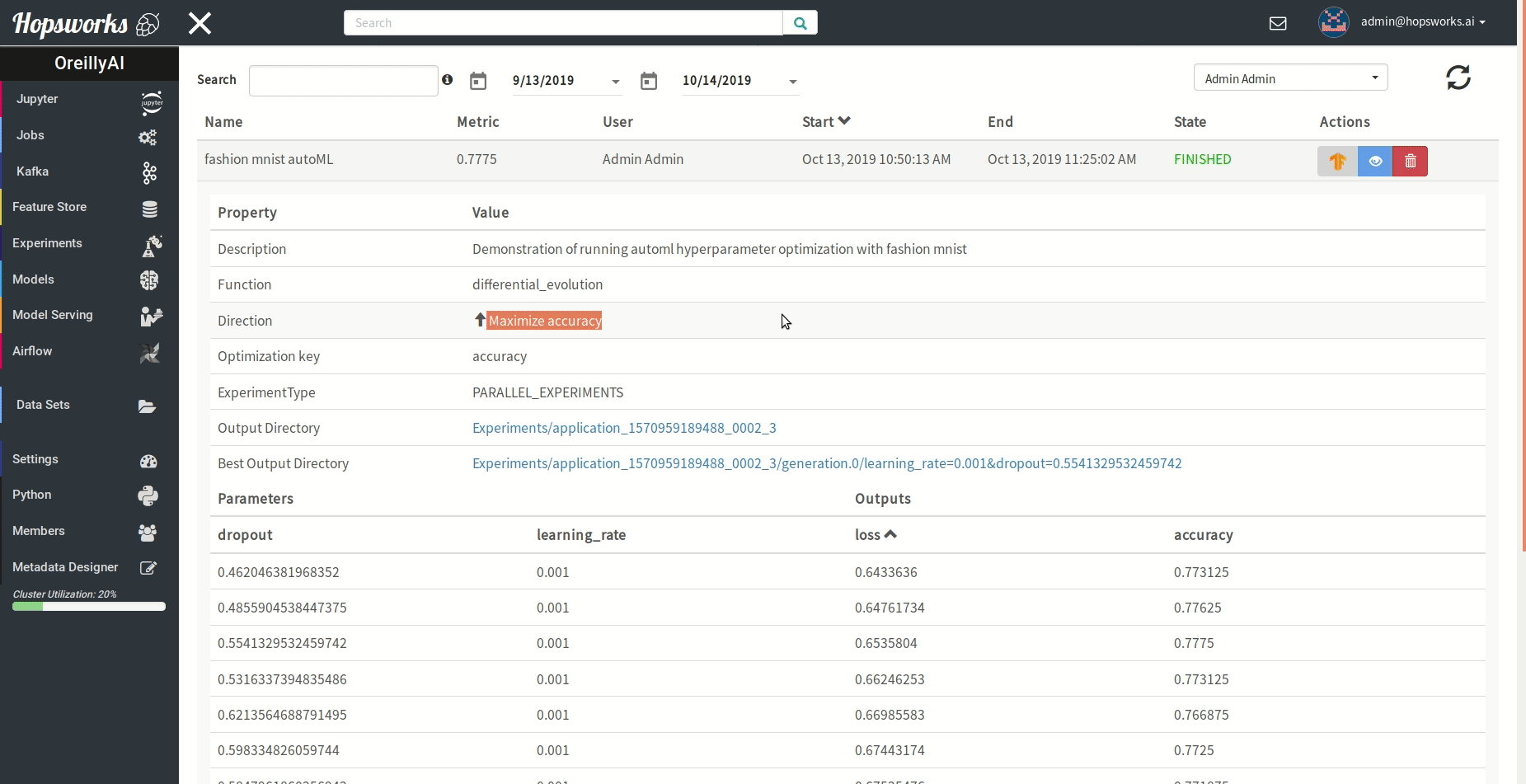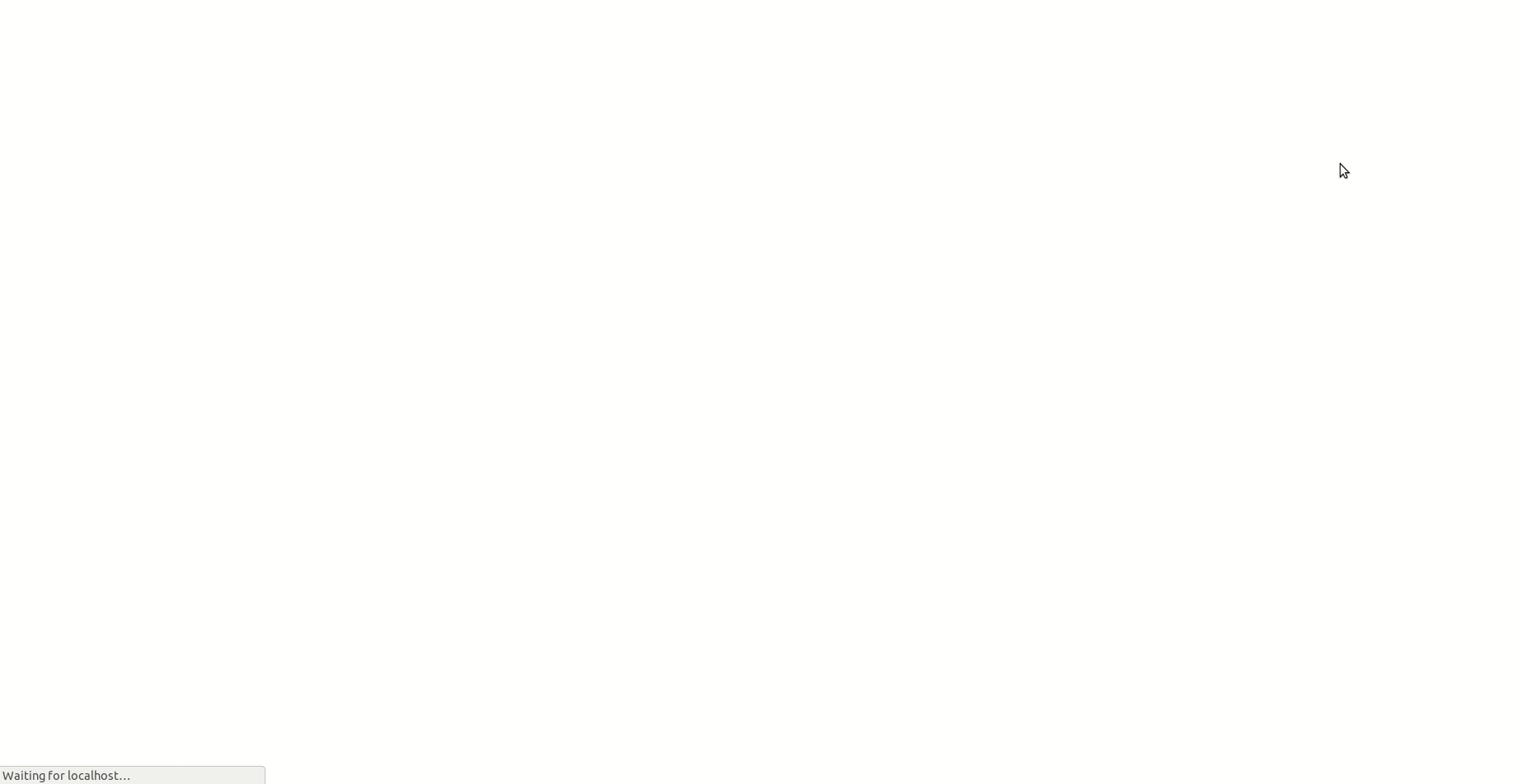
"### Managing experiments\n",
"Experiments service provides a unified view of all the experiments run using the `experiment` module.\n",
" \n",
"As demonstrated in the gif it provides general information about the experiment and the resulting metric. Experiments can be visualized meanwhile or after training in a TensorBoard.\n",
" \n",
" \n",
""
]
},
{
"cell_type": "code",
"execution_count": 7,
"metadata": {},
"outputs": [],
"source": [
"def keras_mnist():\n",
" \n",
" import os\n",
" import sys\n",
" import uuid\n",
" import random\n",
" \n",
" import numpy as np\n",
" \n",
" from tensorflow import keras\n",
" import tensorflow as tf\n",
" from tensorflow.keras.datasets import mnist\n",
" from tensorflow.keras.models import Sequential\n",
" from tensorflow.keras.layers import Dense, Dropout, Flatten\n",
" from tensorflow.keras.layers import Conv2D, MaxPooling2D\n",
" from tensorflow.keras.callbacks import TensorBoard\n",
" from tensorflow.keras import backend as K\n",
"\n",
" import math\n",
" from hops import tensorboard\n",
"\n",
" from hops import model as hops_model\n",
" from hops import hdfs\n",
"\n",
" import pydoop.hdfs as pydoop\n",
" \n",
"\n",
" batch_size=32\n",
" num_classes = 10\n",
"\n",
" \n",
" # Provide path to train and validation datasets\n",
" train_filenames = [hdfs.project_path() + \"TourData/mnist/train/train.tfrecords\"]\n",
" validation_filenames = [hdfs.project_path() + \"TourData/mnist/validation/validation.tfrecords\"]\n",
" \n",
" # Define input function\n",
" def data_input(filenames, batch_size=128, num_classes = 10, shuffle=False, repeat=None):\n",
"\n",
" def parser(serialized_example):\n",
" \"\"\"Parses a single tf.Example into image and label tensors.\"\"\"\n",
" features = tf.io.parse_single_example(\n",
" serialized_example,\n",
" features={\n",
" 'image_raw': tf.io.FixedLenFeature([], tf.string),\n",
" 'label': tf.io.FixedLenFeature([], tf.int64),\n",
" })\n",
" image = tf.io.decode_raw(features['image_raw'], tf.uint8)\n",
" image.set_shape([28 * 28])\n",
"\n",
" # Normalize the values of the image from the range [0, 255] to [-0.5, 0.5]\n",
" image = tf.cast(image, tf.float32) / 255 - 0.5\n",
" label = tf.cast(features['label'], tf.int32)\n",
" \n",
" # Create a one hot array for your labels\n",
" label = tf.one_hot(label, num_classes)\n",
" \n",
" return image, label\n",
"\n",
" # Import MNIST data\n",
" dataset = tf.data.TFRecordDataset(filenames)\n",
"\n",
" # Map the parser over dataset, and batch results by up to batch_size\n",
" dataset = dataset.map(parser)\n",
" if shuffle:\n",
" dataset = dataset.shuffle(buffer_size=128)\n",
" dataset = dataset.batch(batch_size, drop_remainder=True)\n",
" dataset = dataset.repeat(repeat)\n",
" return dataset\n",
"\n",
" # Define a Keras Model.\n",
" model = tf.keras.Sequential()\n",
" model.add(tf.keras.layers.Dense(128, activation='relu', input_shape=(784,)))\n",
" model.add(tf.keras.layers.Dense(num_classes, activation='softmax'))\n",
"\n",
" # Compile the model.\n",
" model.compile(loss=tf.keras.losses.categorical_crossentropy,\n",
" optimizer= tf.keras.optimizers.Adam(0.001),\n",
" metrics=['accuracy']\n",
" )\n",
" \n",
" callbacks = [\n",
" tf.keras.callbacks.TensorBoard(log_dir=tensorboard.logdir()),\n",
" tf.keras.callbacks.ModelCheckpoint(filepath=tensorboard.logdir()),\n",
" ]\n",
" model.fit(data_input(train_filenames, batch_size), \n",
" verbose=0,\n",
" epochs=3, \n",
" steps_per_epoch=5,\n",
" validation_data=data_input(validation_filenames, batch_size),\n",
" validation_steps=1, \n",
" callbacks=callbacks\n",
" )\n",
" \n",
" score = model.evaluate(data_input(validation_filenames, batch_size), steps=1)\n",
"\n",
" # Export model\n",
" # WARNING(break-tutorial-inline-code): The following code snippet is\n",
" # in-lined in tutorials, please update tutorial documents accordingly\n",
" # whenever code changes.\n",
"\n",
" export_path = os.getcwd() + '/model-' + str(uuid.uuid4())\n",
" print('Exporting trained model to: {}'.format(export_path))\n",
" \n",
" tf.saved_model.save(model, export_path)\n",
"\n",
" print('Done exporting!')\n",
" \n",
" metrics = {'accuracy': score[1]}\n",
" \n",
" hops_model.export(export_path, \"mnist\", metrics=metrics) \n",
" \n",
" return metrics"
]
},
{
"cell_type": "code",
"execution_count": 8,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Finished Experiment \n",
"\n",
"('hdfs://rpc.namenode.service.consul:8020/Projects/demo/Experiments/application_1594231828166_0176_4', {'accuracy': 0.59375, 'log': 'Experiments/application_1594231828166_0176_4/output.log'})"
]
}
],
"source": [
"from hops import experiment\n",
"from hops import hdfs\n",
"\n",
"experiment.launch(keras_mnist, name='mnist model', local_logdir=True, metric_key='accuracy')"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": []
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
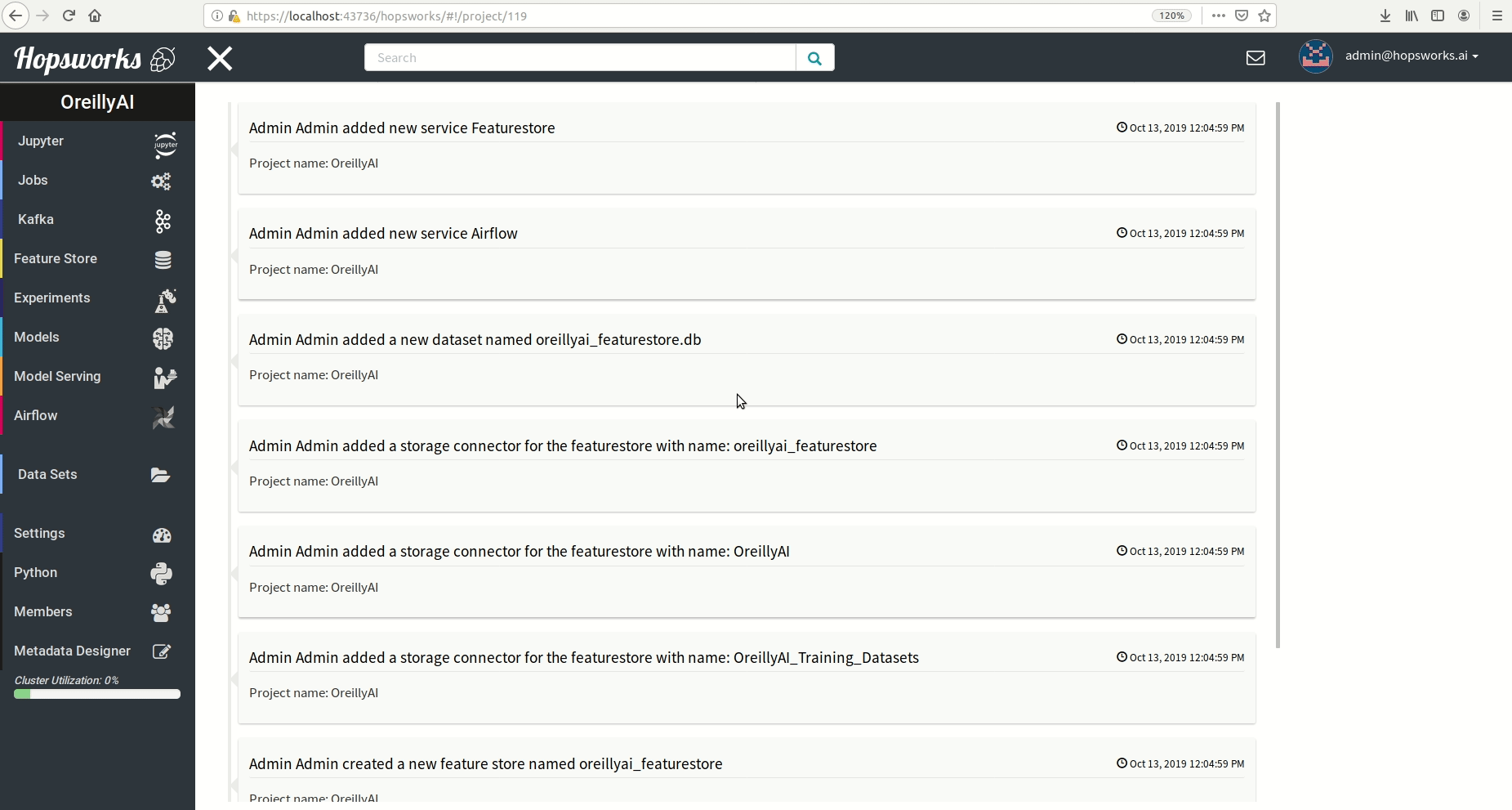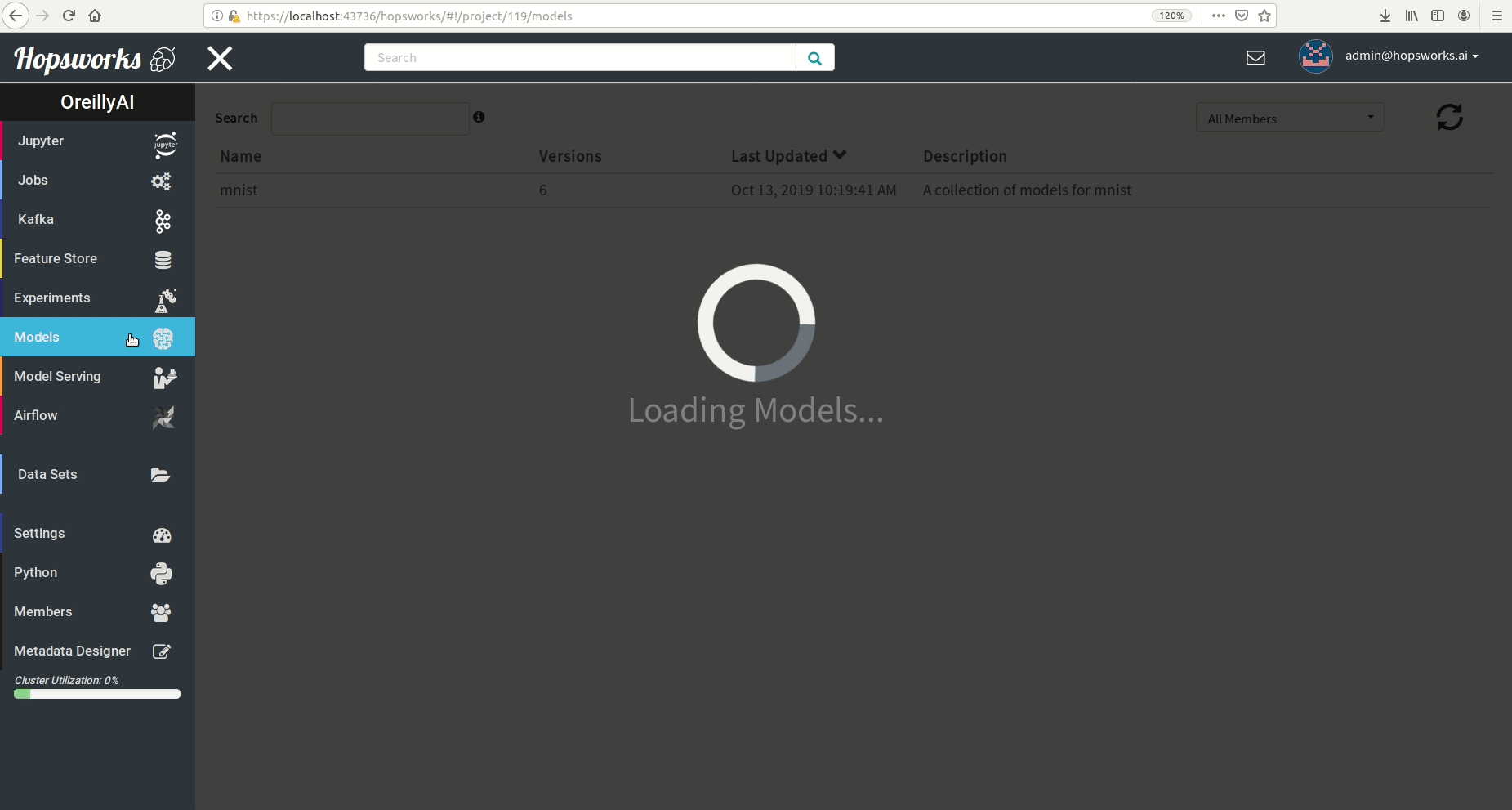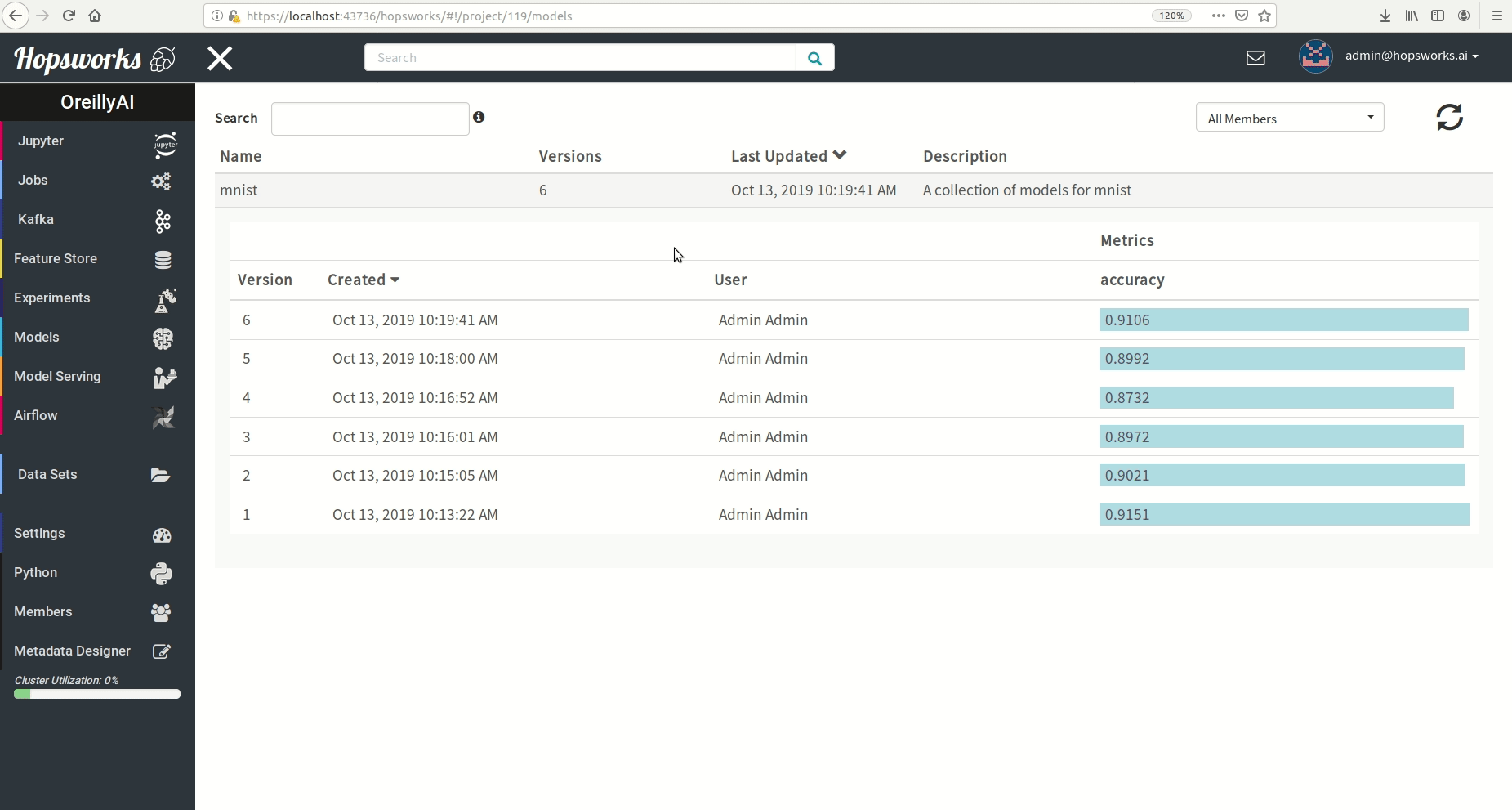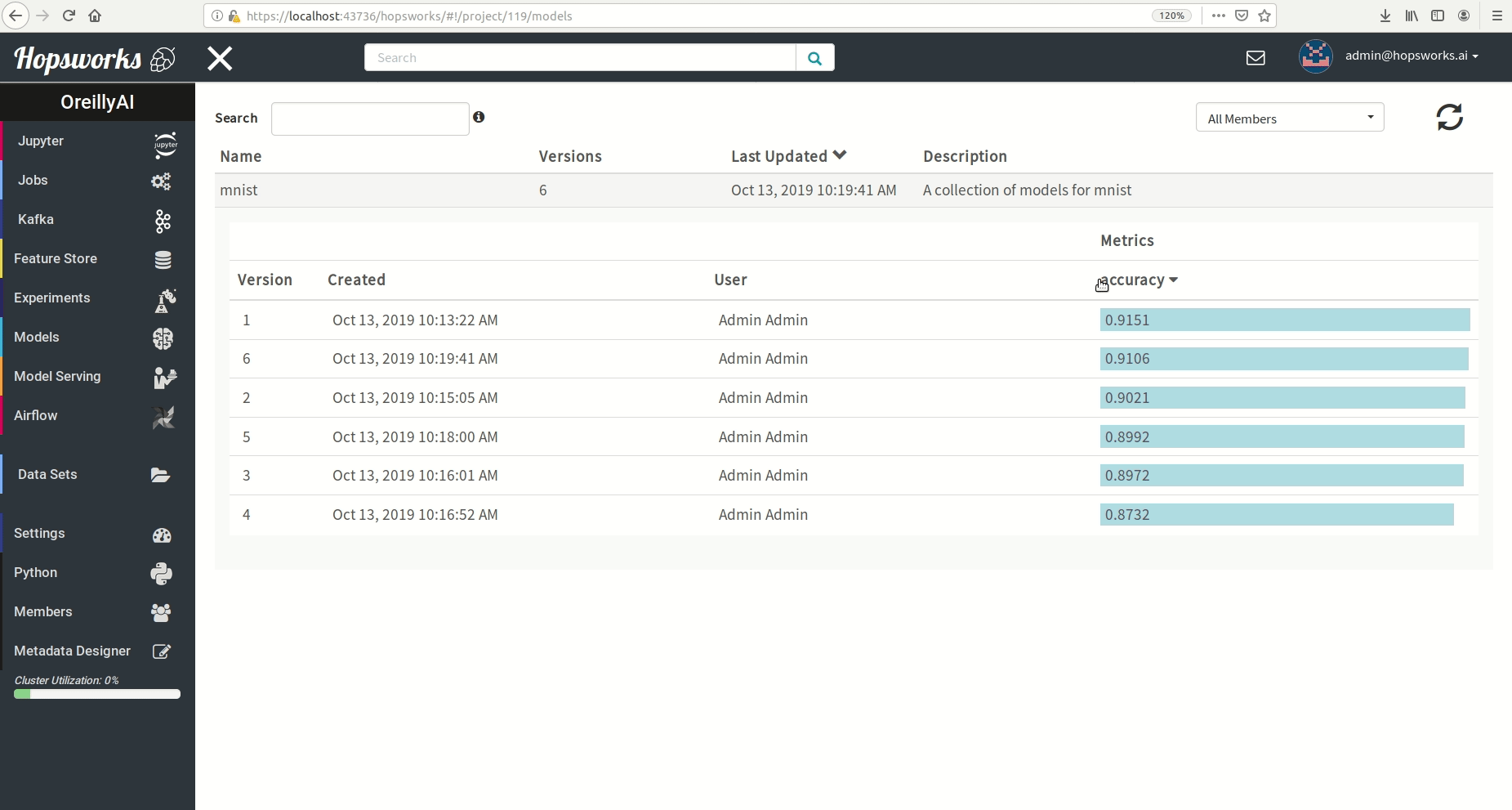
"# Check Model Repository for best model based on accuracy"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Query Model Repository for best mnist Model"
]
},
{
"cell_type": "code",
"execution_count": 9,
"metadata": {},
"outputs": [],
"source": [
"from hops import model\n",
"from hops.model import Metric\n",
"MODEL_NAME=\"mnist\"\n",
"EVALUATION_METRIC=\"accuracy\""
]
},
{
"cell_type": "code",
"execution_count": 10,
"metadata": {},
"outputs": [],
"source": [
"best_model = model.get_best_model(MODEL_NAME, EVALUATION_METRIC, Metric.MAX)"
]
},
{
"cell_type": "code",
"execution_count": 11,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Model name: mnist\n",
"Model version: 1\n",
"{'accuracy': '0.59375'}"
]
}
],
"source": [
"print('Model name: ' + best_model['name'])\n",
"print('Model version: ' + str(best_model['version']))\n",
"print(best_model['metrics'])"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Create Model Serving of Exported Model"
]
},
{
"cell_type": "code",
"execution_count": 12,
"metadata": {},
"outputs": [],
"source": [
"from hops import serving"
]
},
{
"cell_type": "code",
"execution_count": 13,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Creating a serving for model mnist ...\n",
"Serving for model mnist successfully created"
]
}
],
"source": [
"# Create serving\n",
"model_path=\"/Models/\" + best_model['name']\n",
"response = serving.create_or_update(model_path, MODEL_NAME, serving_type=\"TENSORFLOW\", \n",
" model_version=best_model['version'])"
]
},
{
"cell_type": "code",
"execution_count": 14,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"mnist"
]
}
],
"source": [
"# List all available servings in the project\n",
"for s in serving.get_all():\n",
" print(s.name)"
]
},
{
"cell_type": "code",
"execution_count": 15,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"'Stopped'"
]
}
],
"source": [
"# Get serving status\n",
"serving.get_status(MODEL_NAME)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
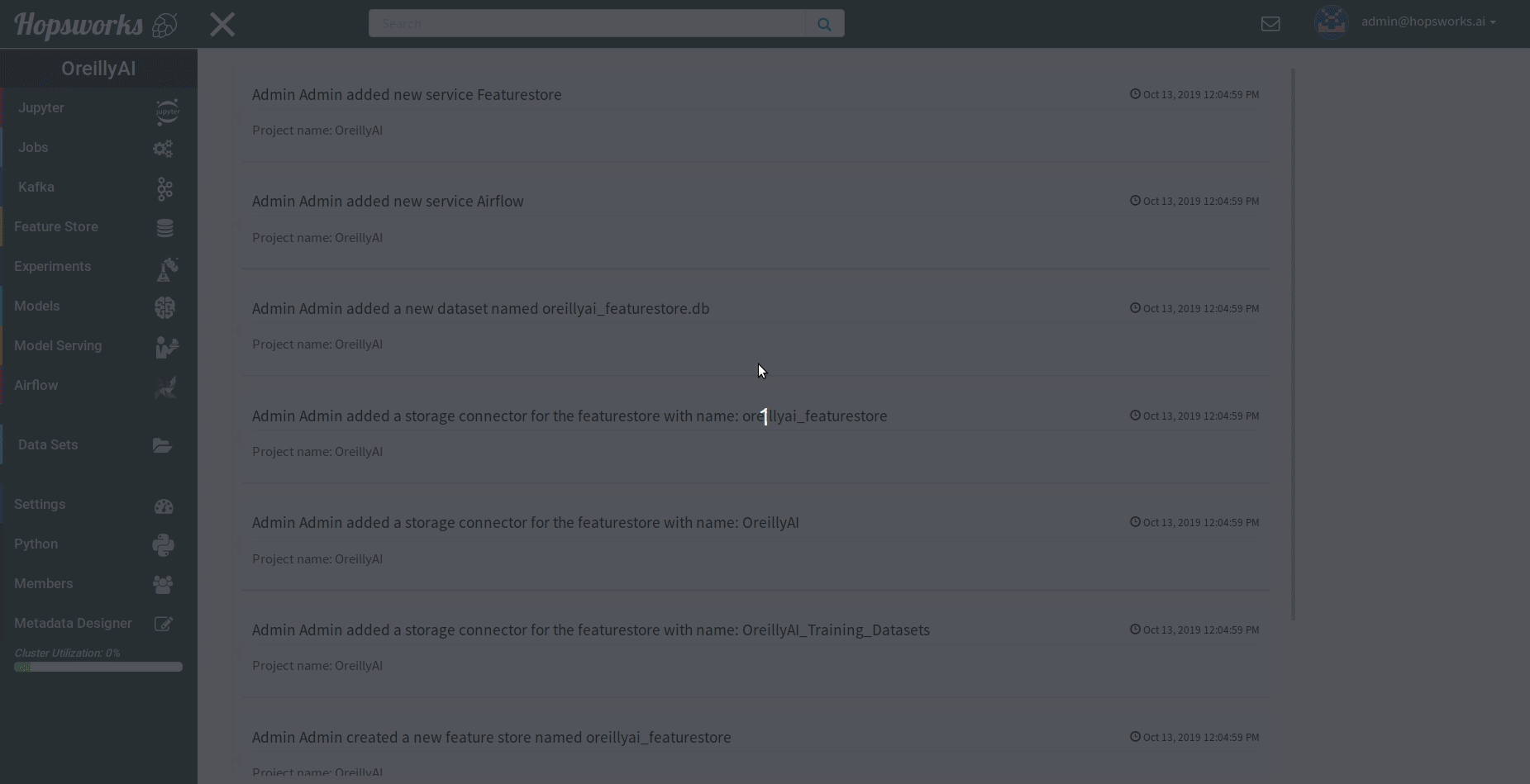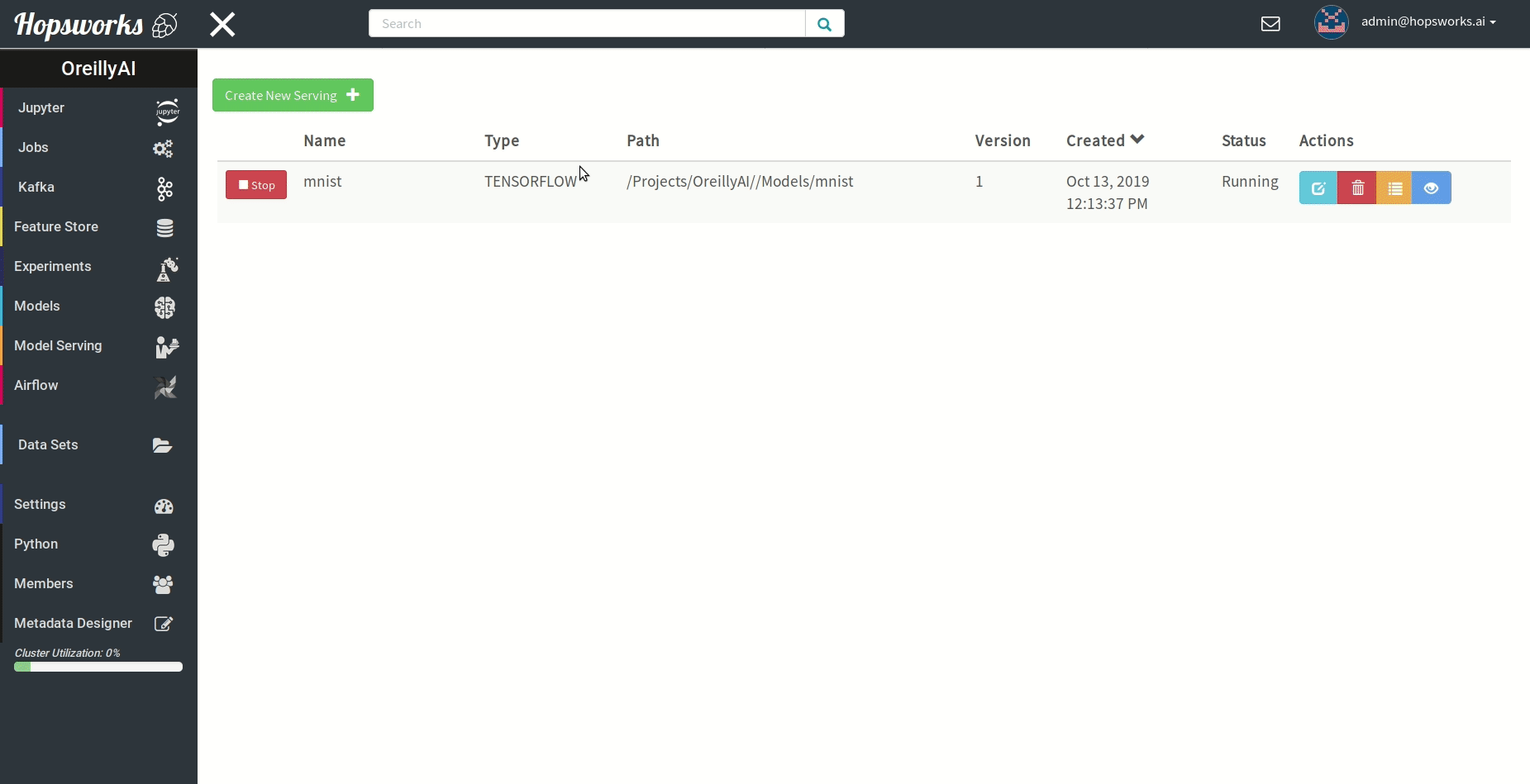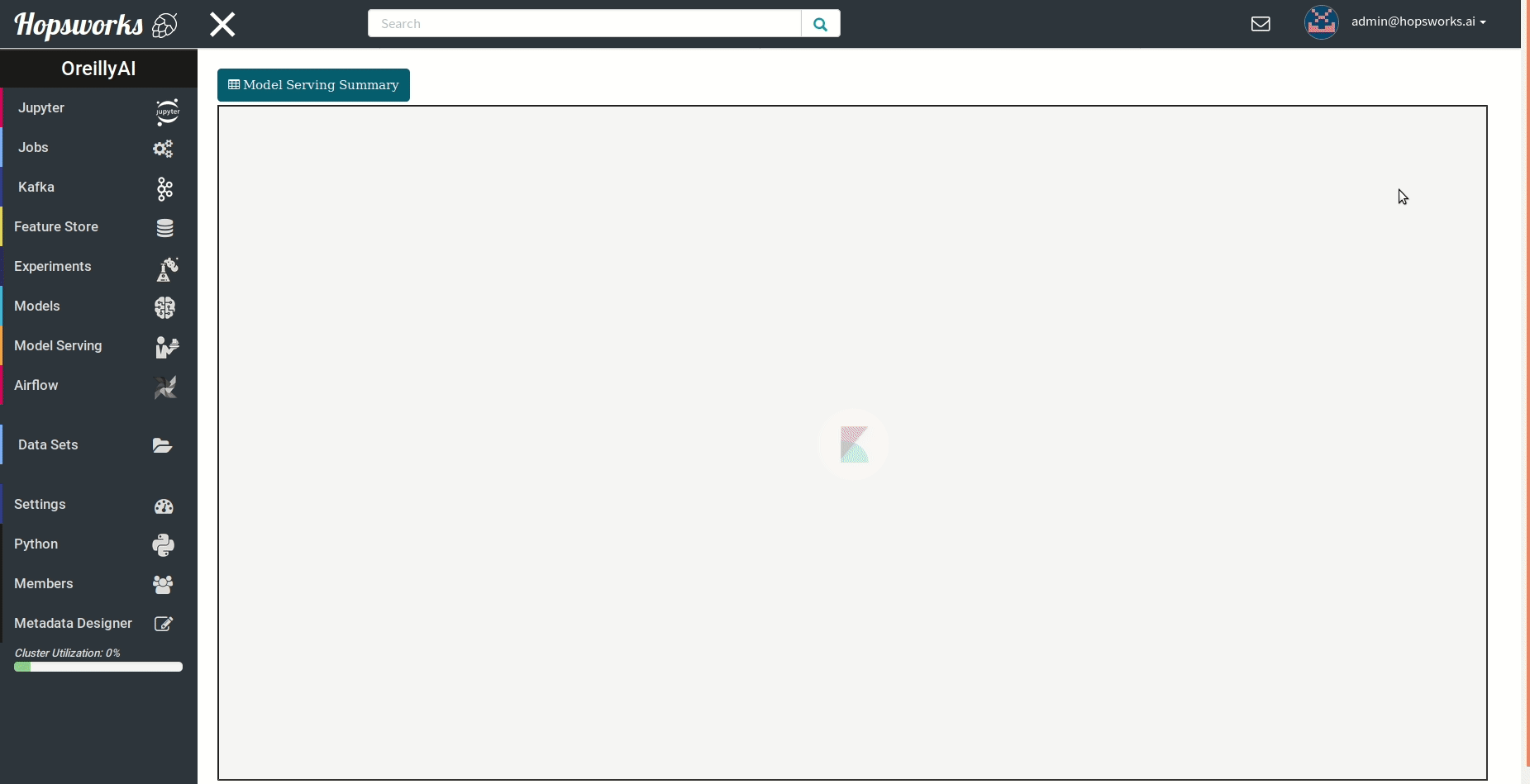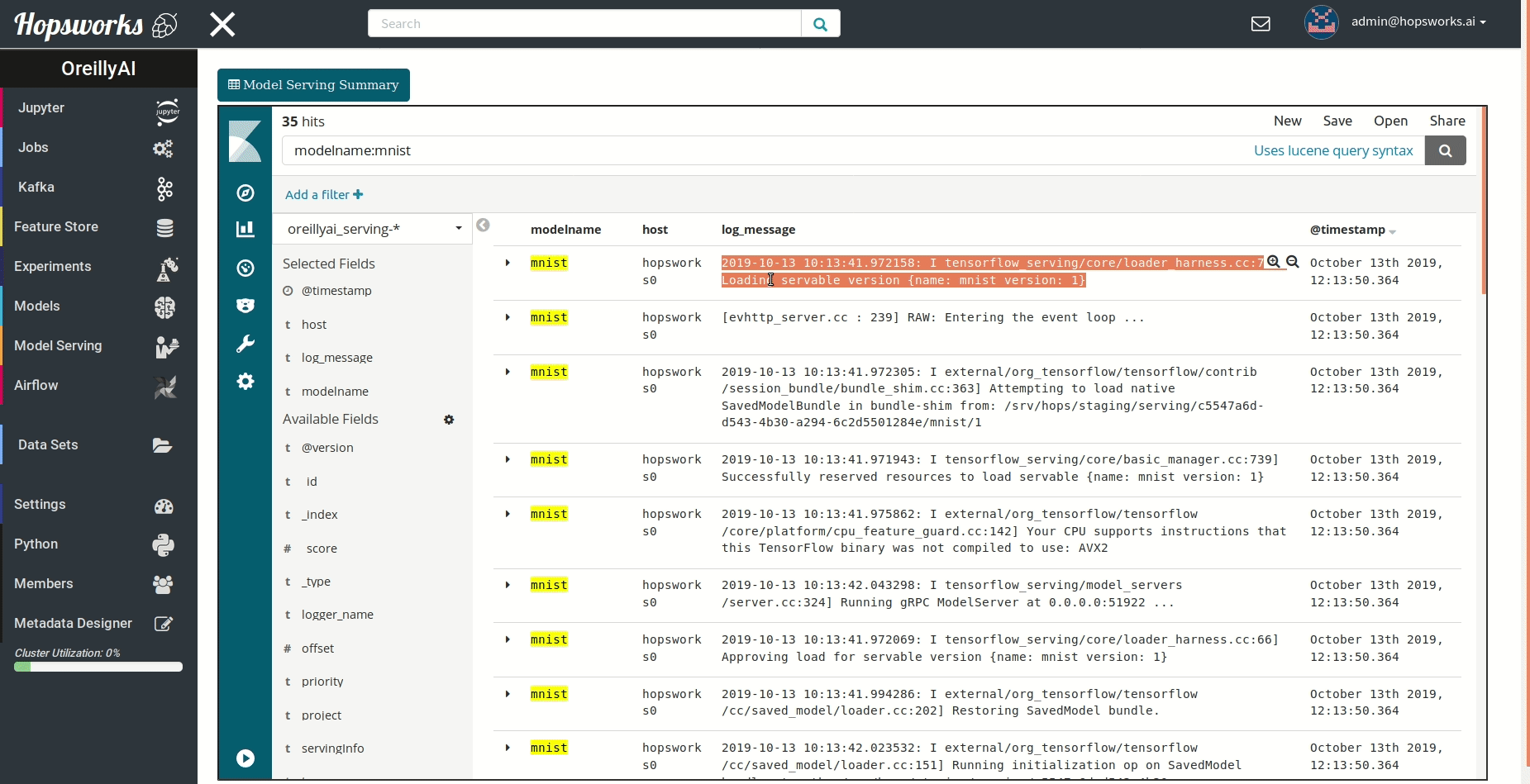
"# Check Model Serving for active servings"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Start Model Serving Server"
]
},
{
"cell_type": "code",
"execution_count": 16,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Starting serving with name: mnist...\n",
"Serving with name: mnist successfully started"
]
}
],
"source": [
"if serving.get_status(MODEL_NAME) == 'Stopped':\n",
" serving.start(MODEL_NAME)"
]
},
{
"cell_type": "code",
"execution_count": 17,
"metadata": {},
"outputs": [],
"source": [
"import time\n",
"while serving.get_status(MODEL_NAME) != \"Running\":\n",
" time.sleep(5) # Let the serving startup correctly\n",
"time.sleep(5)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Send Prediction Requests to the Served Model using Hopsworks REST API"
]
},
{
"cell_type": "code",
"execution_count": 18,
"metadata": {},
"outputs": [],
"source": [
"import numpy as np\n",
"TOPIC_NAME = serving.get_kafka_topic(MODEL_NAME)\n",
"NUM_FEATURES=784"
]
},
{
"cell_type": "code",
"execution_count": 19,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"{'predictions': [[0.00101464614, 0.124517113, 0.63427788, 0.0163144395, 0.0894692615, 0.00116351154, 0.060454987, 0.00864500459, 0.061855197, 0.0022879669]]}\n",
"{'predictions': [[0.00191850925, 0.167059571, 0.551065922, 0.0121973753, 0.101200588, 0.00293193664, 0.0549961925, 0.0213383641, 0.0848787874, 0.00241268263]]}\n",
"{'predictions': [[0.00050952629, 0.151139811, 0.556290507, 0.0104385419, 0.19585146, 0.000732801796, 0.0148065677, 0.028437674, 0.0396146365, 0.00217843778]]}\n",
"{'predictions': [[0.00132977683, 0.165724203, 0.596280158, 0.0154176438, 0.117487162, 0.000765851699, 0.0309293475, 0.0118588647, 0.0586582385, 0.00154881517]]}\n",
"{'predictions': [[0.0010584885, 0.126143798, 0.453216463, 0.0139270639, 0.23464562, 0.0021353832, 0.0354398228, 0.0268977303, 0.101747505, 0.00478807]]}\n",
"{'predictions': [[0.00129793282, 0.10362123, 0.4327223, 0.0191204343, 0.296470761, 0.00151372841, 0.0267837606, 0.00829808, 0.105536826, 0.00463500666]]}\n",
"{'predictions': [[0.000682579936, 0.114368267, 0.538814, 0.00784003, 0.199453488, 0.00151150499, 0.030661013, 0.0139077725, 0.08991687, 0.00284440466]]}\n",
"{'predictions': [[0.000656837947, 0.0822406784, 0.717460692, 0.00662791263, 0.0756253153, 0.000680917408, 0.0238178242, 0.00388909853, 0.0873425603, 0.00165810366]]}\n",
"{'predictions': [[0.000649773749, 0.178170785, 0.654825389, 0.00969067682, 0.0924373269, 0.000525904296, 0.0229914766, 0.00463350257, 0.0342777297, 0.00179741206]]}\n",
"{'predictions': [[0.000734140864, 0.0979306921, 0.637276947, 0.00539853284, 0.174462378, 0.000809073157, 0.0260299761, 0.0069808159, 0.0488583036, 0.00151915126]]}\n",
"{'predictions': [[0.00114852609, 0.0499146283, 0.756860316, 0.017711699, 0.0892188549, 0.00113097276, 0.01615295, 0.00969913, 0.0566330738, 0.00152997614]]}\n",
"{'predictions': [[0.00153077045, 0.122967966, 0.662966549, 0.0150937466, 0.0971821472, 0.00201104418, 0.0421369113, 0.0120321661, 0.0413411036, 0.00273760478]]}\n",
"{'predictions': [[0.00274692359, 0.0863644779, 0.526040792, 0.0319046862, 0.150395423, 0.00108450756, 0.0278904028, 0.0123740099, 0.158668086, 0.00253074407]]}\n",
"{'predictions': [[0.000831353187, 0.120074868, 0.552785456, 0.00987936463, 0.208313331, 0.00213050703, 0.0306558739, 0.0036379518, 0.0693310052, 0.00236020936]]}\n",
"{'predictions': [[0.00284365122, 0.219364971, 0.432664514, 0.020772, 0.200447902, 0.00315438746, 0.0391481072, 0.0192343, 0.0596243665, 0.00274573546]]}\n",
"{'predictions': [[0.00132579298, 0.100847624, 0.510532, 0.0210976154, 0.15261063, 0.00126931153, 0.0468352474, 0.00906759314, 0.153121889, 0.003292243]]}\n",
"{'predictions': [[0.000646409462, 0.083442688, 0.772507727, 0.00991513766, 0.0823320076, 0.000599695952, 0.0104787266, 0.0100289239, 0.0294341184, 0.000614514225]]}\n",
"{'predictions': [[0.000665465312, 0.0924700052, 0.792513669, 0.010322392, 0.0389793031, 0.000798372144, 0.0185041316, 0.00881760195, 0.0334593058, 0.00346980523]]}\n",
"{'predictions': [[0.000999733107, 0.117568776, 0.50835222, 0.00760547444, 0.192571685, 0.000939015415, 0.0373838656, 0.00708322553, 0.125456527, 0.00203944184]]}\n",
"{'predictions': [[0.000852248922, 0.123018786, 0.586152613, 0.00976038538, 0.181206152, 0.00210775784, 0.0333217718, 0.00450159563, 0.0558199398, 0.00325872377]]}"
]
}
],
"source": [
"import json\n",
"for i in range(20):\n",
" data = {\n",
" \"signature_name\": \"serving_default\", \"instances\": [np.random.rand(NUM_FEATURES).tolist()]\n",
" }\n",
" response = serving.make_inference_request(MODEL_NAME, data)\n",
" print(response)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": []
}
],
"metadata": {
"kernelspec": {
"display_name": "PySpark",
"language": "python",
"name": "pysparkkernel"
},
"language_info": {
"codemirror_mode": {
"name": "python",
"version": 3
},
"mimetype": "text/x-python",
"name": "pyspark",
"pygments_lexer": "python3"
}
},
"nbformat": 4,
"nbformat_minor": 4
}