\n",
"\n",
"\n",
"\n",
"\n",
"## The `hops` python module\n",
"\n",
"`hops` is a helper library for Hops that facilitates development by hiding the complexity of running applications and iteracting with services.\n",
"\n",
"Have a feature request or encountered an issue? Please let us know on github.\n",
"\n",
"### Using the `experiment` module\n",
"\n",
"To be able to run your Machine Learning code in Hopsworks, the code for the whole program needs to be provided and put inside a wrapper function. Everything, from importing libraries to reading data and defining the model and running the program needs to be put inside a wrapper function.\n",
"\n",
"The `experiment` module provides an api to Python programs such as TensorFlow, Keras and PyTorch on a Hopsworks on any number of machines and GPUs.\n",
"\n",
"An Experiment could be a single Python program, which we refer to as an **Experiment**. \n",
"\n",
"Grid search or genetic hyperparameter optimization such as differential evolution which runs several Experiments in parallel, which we refer to as **Parallel Experiment**. \n",
"\n",
"ParameterServerStrategy, CollectiveAllReduceStrategy and MultiworkerMirroredStrategy making multi-machine/multi-gpu training as simple as invoking a function for orchestration. This mode is referred to as **Distributed Training**.\n",
"\n",
"### Using the `tensorboard` module\n",
"The `tensorboard` module allow us to get the log directory for summaries and checkpoints to be written to the TensorBoard we will see in a bit. The only function that we currently need to call is `tensorboard.logdir()`, which returns the path to the TensorBoard log directory. Furthermore, the content of this directory will be put in as a Dataset in your project's Experiments folder.\n",
"\n",
"The directory could in practice be used to store other data that should be accessible after the experiment is finished.\n",
"```python\n",
"# Use this module to get the TensorBoard logdir\n",
"from hops import tensorboard\n",
"tensorboard_logdir = tensorboard.logdir()\n",
"```\n",
"\n",
"### Using the `hdfs` module\n",
"The `hdfs` module provides a method to get the path in HopsFS where your data is stored, namely by calling `hdfs.project_path()`. The path resolves to the root path for your project, which is the view that you see when you click `Data Sets` in HopsWorks. To point where your actual data resides in the project you to append the full path from there to your Dataset. For example if you create a mnist folder in your Resources Dataset, the path to the mnist data would be `hdfs.project_path() + 'Resources/mnist'`\n",
"\n",
"```python\n",
"# Use this module to get the path to your project in HopsFS, then append the path to your Dataset in your project\n",
"from hops import hdfs\n",
"project_path = hdfs.project_path()\n",
"```\n",
"\n",
"```python\n",
"# Downloading the mnist dataset to the current working directory\n",
"from hops import hdfs\n",
"mnist_hdfs_path = hdfs.project_path() + \"Resources/mnist\"\n",
"local_mnist_path = hdfs.copy_to_local(mnist_hdfs_path)\n",
"```\n",
"\n",
"### Documentation\n",
"See the following links to learn more about running experiments in Hopsworks\n",
"\n",
"- Learn more about experiments\n",
" \n",
"- Building End-To-End pipelines\n",
" \n",
"- Give us a star, create an issue or a feature request on Hopsworks github\n",
"\n",
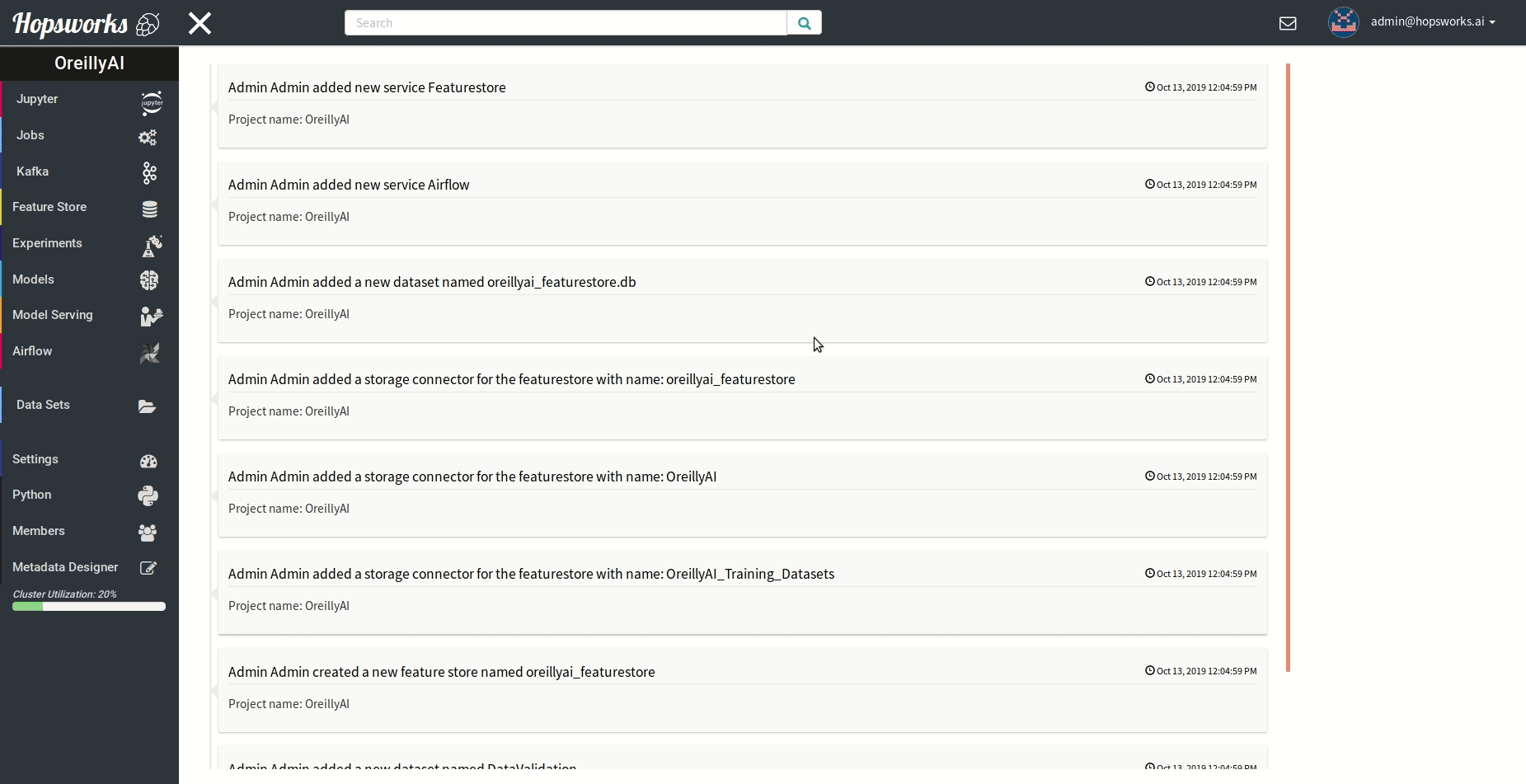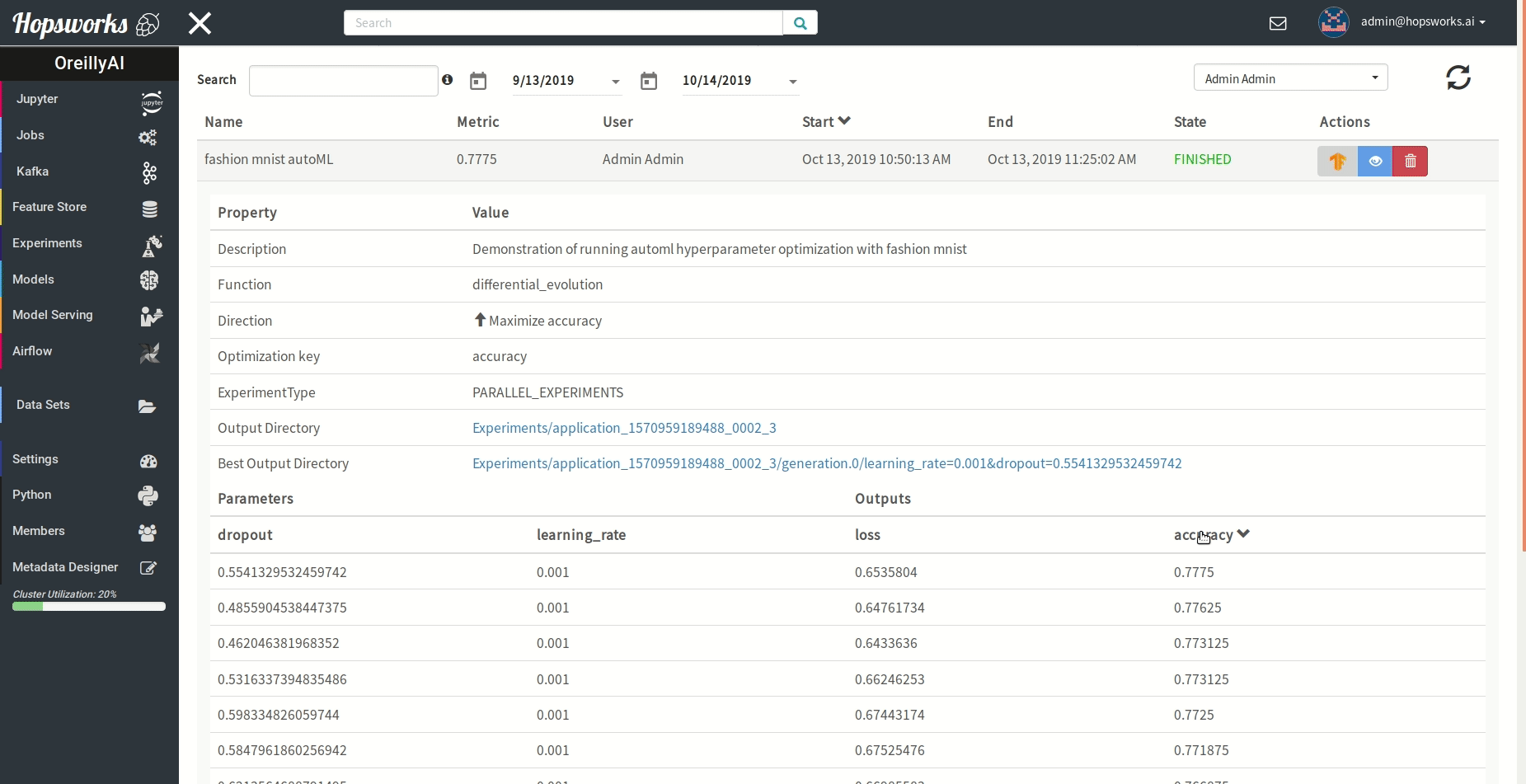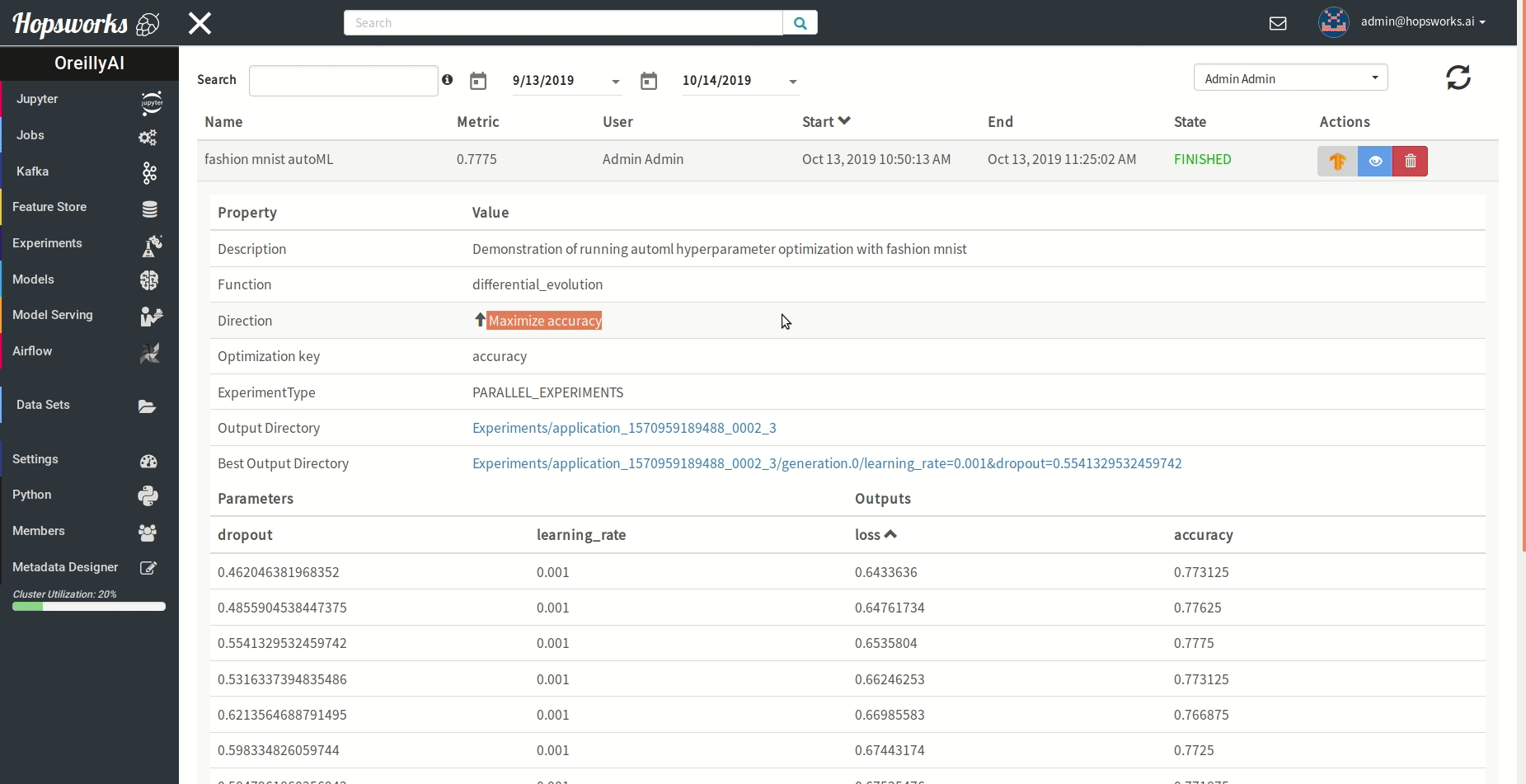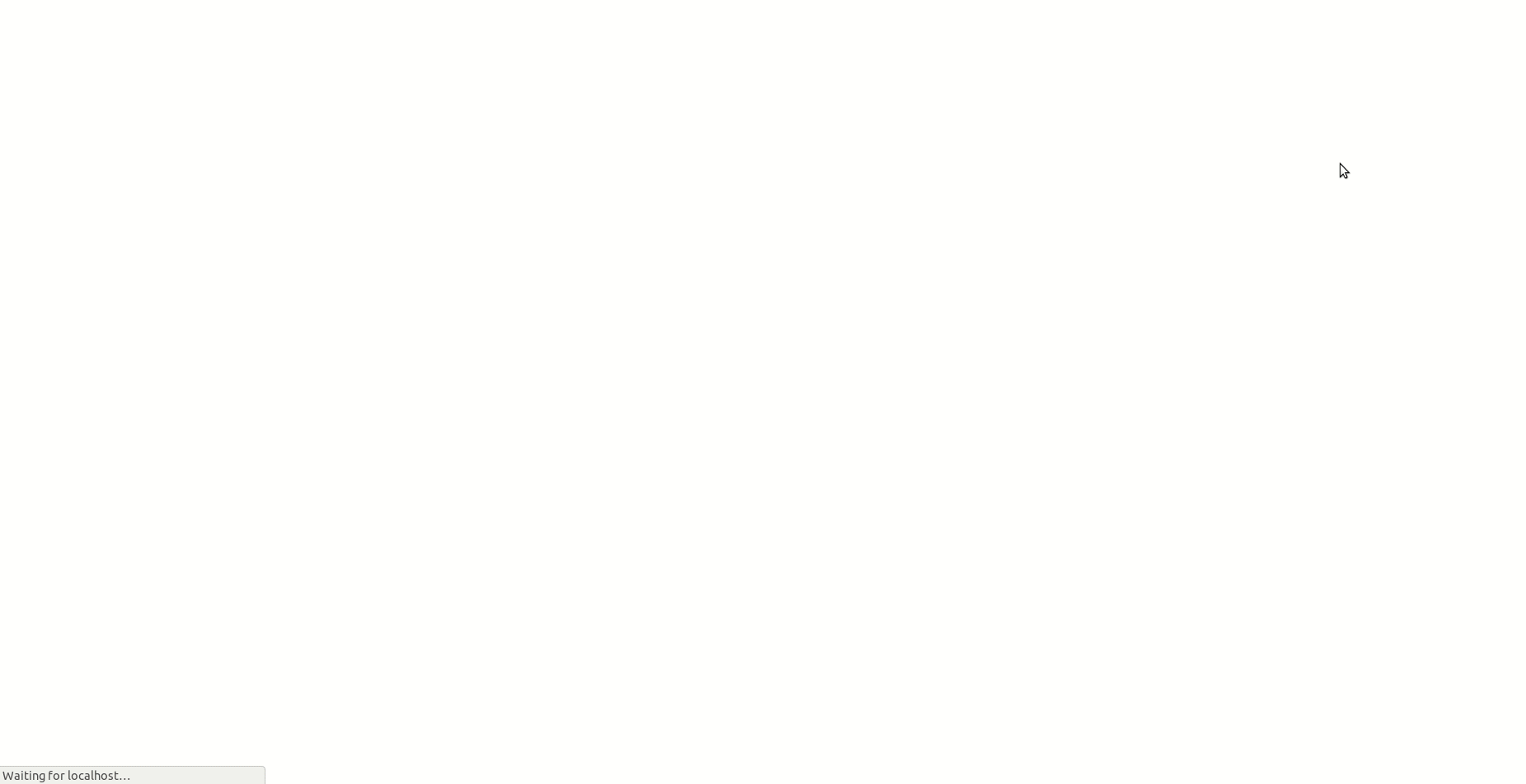
"### Managing experiments\n",
"Experiments service provides a unified view of all the experiments run using the `experiment` module.\n",
" \n",
"As demonstrated in the gif it provides general information about the experiment and the resulting metric. Experiments can be visualized meanwhile or after training in a TensorBoard.\n",
" \n",
" \n",
""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Training Fashion Mnist on Hops "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"def wrapper(learning_rate, dropout):\n",
"\n",
" import tensorflow as tf\n",
" import numpy as np\n",
" from hops import tensorboard\n",
" from hops import hdfs\n",
"\n",
" # Training Parameters\n",
" num_steps = 200\n",
" batch_size = 10\n",
"\n",
" # Network Parameters\n",
" num_input = 784 # MNIST data input (img shape: 28*28)\n",
" num_classes = 10 # MNIST total classes (0-9 digits)\n",
"\n",
" train_filenames = [hdfs.project_path() + \"TourData/mnist/train/train.tfrecords\"]\n",
" validation_filenames = [hdfs.project_path() + \"TourData/mnist/validation/validation.tfrecords\"]\n",
"\n",
" # Create the neural network\n",
" # TF Estimator input is a dict, in case of multiple inputs\n",
" def conv_net(x, n_classes, dropout, reuse, is_training):\n",
"\n",
" # Define a scope for reusing the variables\n",
" with tf.variable_scope('ConvNet', reuse=reuse):\n",
"\n",
" # MNIST data input is a 1-D vector of 784 features (28*28 pixels)\n",
" # Reshape to match picture format [Height x Width x Channel]\n",
" # Tensor input become 4-D: [Batch Size, Height, Width, Channel]\n",
" x = tf.reshape(x, shape=[-1, 28, 28, 1])\n",
"\n",
" # Convolution Layer with 32 filters and a kernel size of 5\n",
" conv1 = tf.layers.conv2d(x, 32, 2, activation=tf.nn.relu)\n",
" # Max Pooling (down-sampling) with strides of 2 and kernel size of 2\n",
" conv1 = tf.layers.max_pooling2d(conv1, 2, 2)\n",
"\n",
" # Convolution Layer with 32 filters and a kernel size of 5\n",
" conv2 = tf.layers.conv2d(conv1, 64, 2, activation=tf.nn.relu)\n",
" # Max Pooling (down-sampling) with strides of 2 and kernel size of 2\n",
" conv2 = tf.layers.max_pooling2d(conv2, 2, 2)\n",
"\n",
" # Flatten the data to a 1-D vector for the fully connected layer\n",
" fc1 = tf.contrib.layers.flatten(conv2)\n",
"\n",
" # Fully connected layer (in tf contrib folder for now)\n",
" fc1 = tf.layers.dense(fc1, 1024)\n",
" # Apply Dropout (if is_training is False, dropout is not applied)\n",
" fc1 = tf.layers.dropout(fc1, rate=dropout, training=is_training)\n",
"\n",
" # Output layer, class prediction\n",
" out = tf.layers.dense(fc1, n_classes)\n",
"\n",
" return out\n",
"\n",
"\n",
" # Define the model function (following TF Estimator Template)\n",
" def model_fn(features, labels, mode, params):\n",
"\n",
" # Build the neural network\n",
" # Because Dropout have different behavior at training and prediction time, we\n",
" # need to create 2 distinct computation graphs that still share the same weights.\n",
" logits_train = conv_net(features, num_classes, dropout, reuse=False, is_training=True)\n",
" logits_test = conv_net(features, num_classes, dropout, reuse=True, is_training=False)\n",
"\n",
" # Predictions\n",
" pred_classes = tf.argmax(logits_test, axis=1)\n",
" pred_probas = tf.nn.softmax(logits_test)\n",
"\n",
" # If prediction mode, early return\n",
" if mode == tf.estimator.ModeKeys.PREDICT:\n",
" return tf.estimator.EstimatorSpec(mode, predictions=pred_classes)\n",
"\n",
" # Define loss and optimizer\n",
" loss_op = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(logits=logits_train, \n",
" labels=tf.cast(labels, dtype=tf.int32)))\n",
" \n",
" optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate)\n",
" train_op = optimizer.minimize(loss_op, global_step=tf.train.get_global_step())\n",
"\n",
" # Evaluate the accuracy of the model\n",
" acc_op = tf.metrics.accuracy(labels=labels, predictions=pred_classes)\n",
"\n",
" image = tf.reshape(features[:10], [-1, 28, 28, 1])\n",
" tf.summary.image(\"image\", image)\n",
"\n",
" # TF Estimators requires to return a EstimatorSpec, that specify\n",
" # the different ops for training, evaluating, ...\n",
" estim_specs = tf.estimator.EstimatorSpec(\n",
" mode=mode,\n",
" predictions=pred_classes,\n",
" loss=loss_op,\n",
" train_op=train_op,\n",
" eval_metric_ops={'accuracy': acc_op})\n",
"\n",
" return estim_specs\n",
"\n",
"\n",
" def data_input_fn(filenames, batch_size=128, shuffle=False, repeat=None):\n",
"\n",
" def parser(serialized_example):\n",
" \"\"\"Parses a single tf.Example into image and label tensors.\"\"\"\n",
" features = tf.parse_single_example(\n",
" serialized_example,\n",
" features={\n",
" 'image_raw': tf.FixedLenFeature([], tf.string),\n",
" 'label': tf.FixedLenFeature([], tf.int64),\n",
" })\n",
" image = tf.decode_raw(features['image_raw'], tf.uint8)\n",
" image.set_shape([28 * 28])\n",
"\n",
" # Normalize the values of the image from the range [0, 255] to [-0.5, 0.5]\n",
" image = tf.cast(image, tf.float32) / 255 - 0.5\n",
" label = tf.cast(features['label'], tf.int32)\n",
" return image, label\n",
"\n",
" def _input_fn():\n",
" # Import MNIST data\n",
" dataset = tf.data.TFRecordDataset(filenames)\n",
"\n",
" # Map the parser over dataset, and batch results by up to batch_size\n",
" dataset = dataset.map(parser)\n",
" if shuffle:\n",
" dataset = dataset.shuffle(buffer_size=128)\n",
" dataset = dataset.batch(batch_size)\n",
" dataset = dataset.repeat(repeat)\n",
" iterator = dataset.make_one_shot_iterator()\n",
"\n",
" features, labels = iterator.get_next()\n",
"\n",
" return features, labels\n",
"\n",
" return _input_fn\n",
"\n",
"\n",
" run_config = tf.contrib.learn.RunConfig(\n",
" model_dir=tensorboard.logdir(),\n",
" save_checkpoints_steps=10,\n",
" save_summary_steps=10,\n",
" log_step_count_steps=10)\n",
"\n",
" hparams = tf.contrib.training.HParams(\n",
" learning_rate=learning_rate, dropout_rate=dropout)\n",
"\n",
" summary_hook = tf.train.SummarySaverHook(\n",
" save_steps = run_config.save_summary_steps,\n",
" scaffold= tf.train.Scaffold(),\n",
" summary_op=tf.summary.merge_all())\n",
"\n",
" mnist_estimator = tf.estimator.Estimator(\n",
" model_fn=model_fn,\n",
" config=run_config,\n",
" params=hparams\n",
" )\n",
"\n",
"\n",
" train_input_fn = data_input_fn(train_filenames[0], batch_size=batch_size)\n",
" eval_input_fn = data_input_fn(validation_filenames[0], batch_size=batch_size)\n",
"\n",
" experiment = tf.contrib.learn.Experiment(\n",
" mnist_estimator,\n",
" train_input_fn=train_input_fn,\n",
" eval_input_fn=eval_input_fn,\n",
" train_steps=num_steps,\n",
" min_eval_frequency=10,\n",
" eval_hooks=[summary_hook]\n",
" )\n",
"\n",
" experiment.train_and_evaluate()\n",
" \n",
" evaluate = mnist_estimator.evaluate(input_fn=eval_input_fn, steps=num_steps)\n",
" accuracy = evaluate[\"accuracy\"]\n",
" loss = evaluate[\"loss\"]\n",
" \n",
" return {'accuracy': accuracy, 'loss': loss}\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Hyperparameter search \n",
"\n",
"Hyperparameter optimization is critical to achieve the best accuracy for your model. With Hops, hyperparameter optimization is easier than ever. We can find the best hyperparameters to train the model and make it easy to find the best set of hyper parameters by visualizing them in TensorBoard for you."
]
},
{
"cell_type": "code",
"execution_count": 2,
"metadata": {
"scrolled": true
},
"outputs": [],
"source": [
"#Define dict for hyperparameters\n",
"search_dict = {'learning_rate': [0.001, 0.0001], 'dropout': [0.45, 0.7]}"
]
},
{
"cell_type": "code",
"execution_count": 3,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"/hopsworks-api/api/project/119/experiments/application_1571078644231_0003_1?xattr=CREATE\n",
"\n",
"Generation 1 || average metric: 0.7899, best metric: 0.8075, best parameter combination: ['learning_rate=0.001', 'dropout=0.5813233111981606']\n",
"\n",
"Generation 2 || average metric: 0.7899, best metric: 0.8075, best parameter combination: ['learning_rate=0.001', 'dropout=0.5813233111981606']\n",
"\n",
"Generation 3 || average metric: 0.7899, best metric: 0.8075, best parameter combination: ['learning_rate=0.001', 'dropout=0.5813233111981606']\n",
"\n",
"Generation 4 || average metric: 0.7899, best metric: 0.8075, best parameter combination: ['learning_rate=0.001', 'dropout=0.5813233111981606']\n",
"\n",
"Finished Experiment \n",
"\n",
"/hopsworks-api/api/project/119/experiments/application_1571078644231_0003_1?xattr=REPLACE\n",
"\n",
"('hdfs://10.0.2.15:8020/Projects/OreillyAI/Experiments/application_1571078644231_0003_1/generation.1/learning_rate=0.001&dropout=0.5813233111981606', {'learning_rate': '0.001', 'dropout': '0.5813233111981606'}, {'accuracy': '0.8075', 'loss': '0.58013296'})"
]
}
],
"source": [
"from hops import experiment\n",
"from hops import hdfs\n",
"\n",
"experiment.differential_evolution(\n",
" wrapper, \n",
" search_dict, \n",
" direction='max', \n",
" generations=4, \n",
" population=5, \n",
" name='fashion mnist autoML', \n",
" optimization_key='accuracy',\n",
" description='Demonstration of running automl hyperparameter optimization with fashion mnist',\n",
" local_logdir=True\n",
")"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "PySpark",
"language": "",
"name": "pysparkkernel"
},
"language_info": {
"codemirror_mode": {
"name": "python",
"version": 2
},
"mimetype": "text/x-python",
"name": "pyspark",
"pygments_lexer": "ipython3"
}
},
"nbformat": 4,
"nbformat_minor": 4
}