\n",
"\n",
"\n",
"\n",
"\n",
"## The `hops` python module\n",
"\n",
"`hops` is a helper library for Hops that facilitates development by hiding the complexity of running applications and iteracting with services.\n",
"\n",
"Have a feature request or encountered an issue? Please let us know on github.\n",
"\n",
"### Using the `experiment` module\n",
"\n",
"To be able to run your Machine Learning code in Hopsworks, the code for the whole program needs to be provided and put inside a wrapper function. Everything, from importing libraries to reading data and defining the model and running the program needs to be put inside a wrapper function.\n",
"\n",
"The `experiment` module provides an api to Python programs such as TensorFlow, Keras and PyTorch on a Hopsworks on any number of machines and GPUs.\n",
"\n",
"An Experiment could be a single Python program, which we refer to as an **Experiment**. \n",
"\n",
"Grid search or genetic hyperparameter optimization such as differential evolution which runs several Experiments in parallel, which we refer to as **Parallel Experiment**. \n",
"\n",
"ParameterServerStrategy, CollectiveAllReduceStrategy and MultiworkerMirroredStrategy making multi-machine/multi-gpu training as simple as invoking a function for orchestration. This mode is referred to as **Distributed Training**.\n",
"\n",
"### Using the `tensorboard` module\n",
"The `tensorboard` module allow us to get the log directory for summaries and checkpoints to be written to the TensorBoard we will see in a bit. The only function that we currently need to call is `tensorboard.logdir()`, which returns the path to the TensorBoard log directory. Furthermore, the content of this directory will be put in as a Dataset in your project's Experiments folder.\n",
"\n",
"The directory could in practice be used to store other data that should be accessible after the experiment is finished.\n",
"```python\n",
"# Use this module to get the TensorBoard logdir\n",
"from hops import tensorboard\n",
"tensorboard_logdir = tensorboard.logdir()\n",
"```\n",
"\n",
"### Using the `hdfs` module\n",
"The `hdfs` module provides a method to get the path in HopsFS where your data is stored, namely by calling `hdfs.project_path()`. The path resolves to the root path for your project, which is the view that you see when you click `Data Sets` in HopsWorks. To point where your actual data resides in the project you to append the full path from there to your Dataset. For example if you create a mnist folder in your Resources Dataset, the path to the mnist data would be `hdfs.project_path() + 'Resources/mnist'`\n",
"\n",
"```python\n",
"# Use this module to get the path to your project in HopsFS, then append the path to your Dataset in your project\n",
"from hops import hdfs\n",
"project_path = hdfs.project_path()\n",
"```\n",
"\n",
"```python\n",
"# Downloading the mnist dataset to the current working directory\n",
"from hops import hdfs\n",
"mnist_hdfs_path = hdfs.project_path() + \"Resources/mnist\"\n",
"local_mnist_path = hdfs.copy_to_local(mnist_hdfs_path)\n",
"```\n",
"\n",
"### Documentation\n",
"See the following links to learn more about running experiments in Hopsworks\n",
"\n",
"- Learn more about experiments\n",
" \n",
"- Building End-To-End pipelines\n",
" \n",
"- Give us a star, create an issue or a feature request on Hopsworks github\n",
"\n",
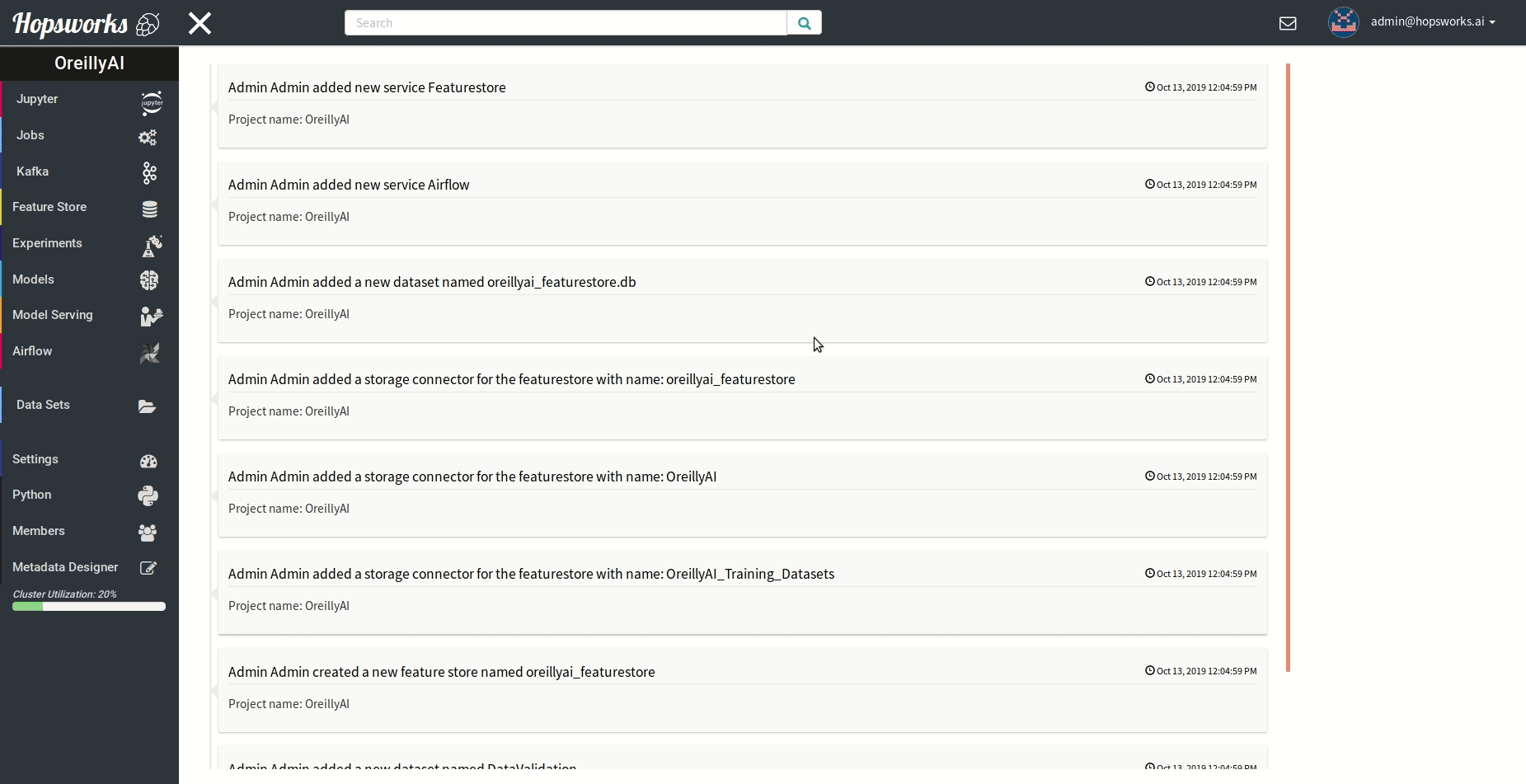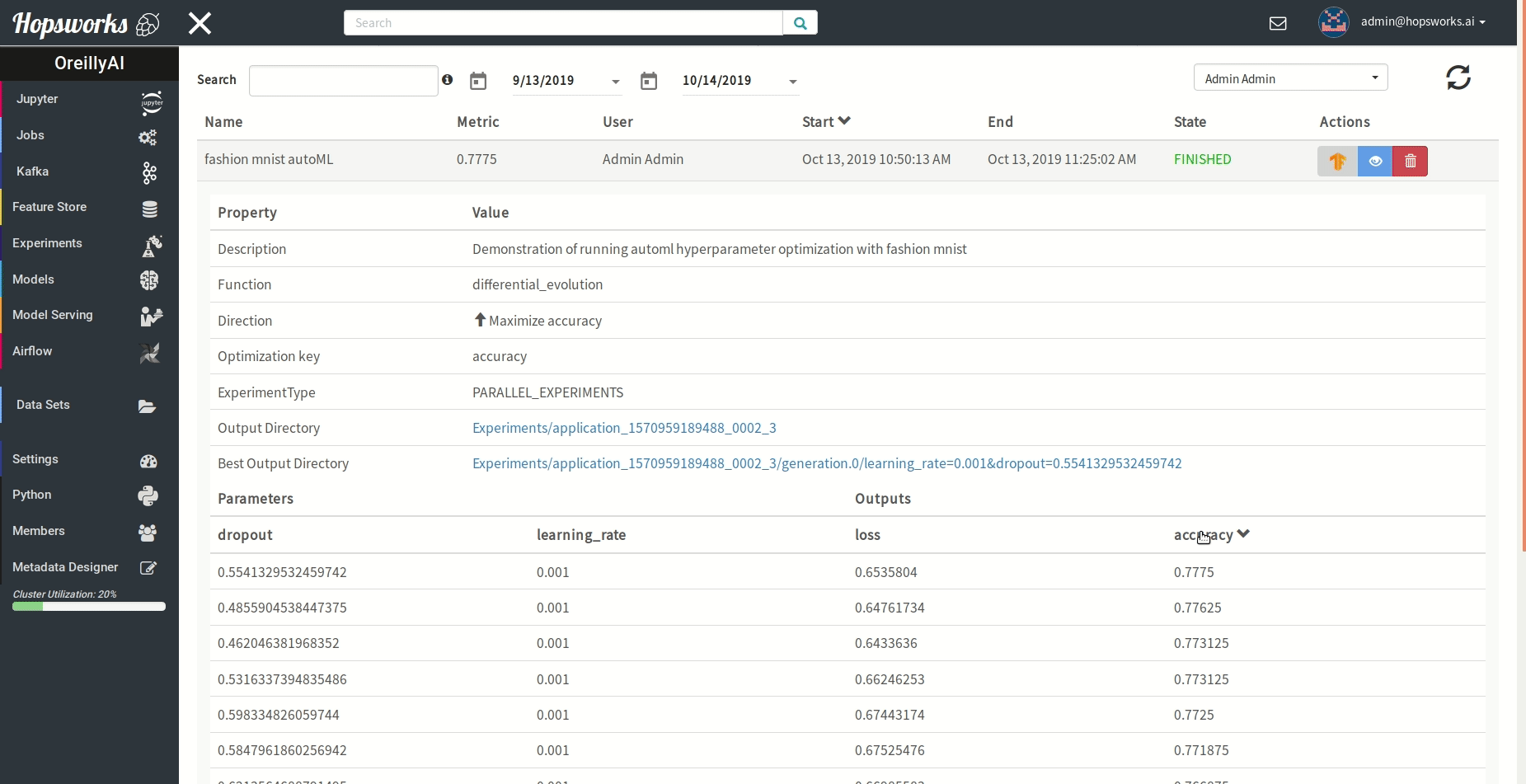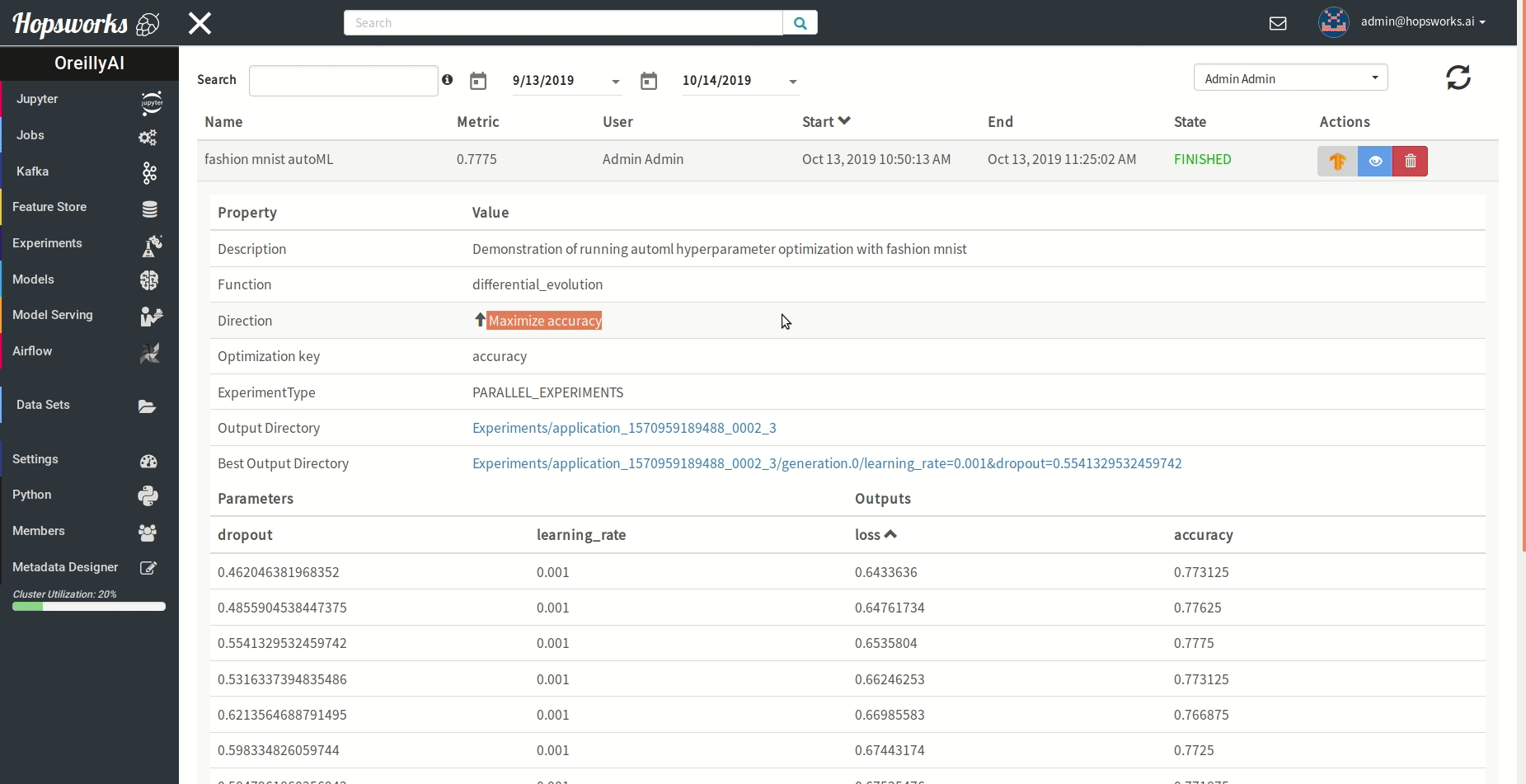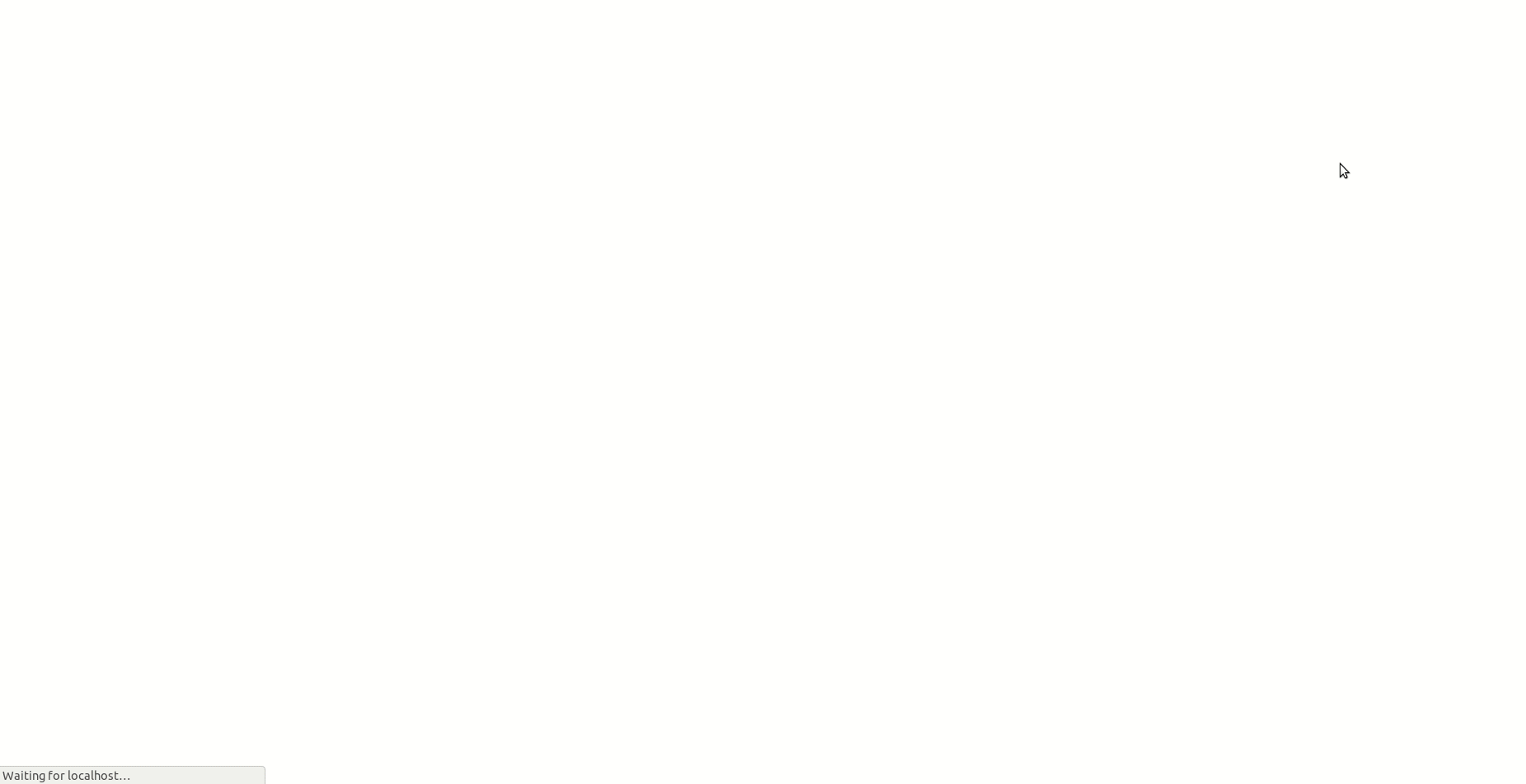
"### Managing experiments\n",
"Experiments service provides a unified view of all the experiments run using the `experiment` module.\n",
" \n",
"As demonstrated in the gif it provides general information about the experiment and the resulting metric. Experiments can be visualized meanwhile or after training in a TensorBoard.\n",
" \n",
" \n",
""
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"def wrapper(lr, momentum):\n",
" import argparse\n",
" import torch\n",
" import torch.nn as nn\n",
" import torch.nn.functional as F\n",
" import torch.optim as optim\n",
" from torchvision import datasets, transforms\n",
" from torch.utils.tensorboard import SummaryWriter \n",
" import os\n",
" from hops import tensorboard\n",
" from hops import hdfs\n",
"\n",
"\n",
" class Net(nn.Module):\n",
" def __init__(self):\n",
" super(Net, self).__init__()\n",
" self.conv1 = nn.Conv2d(1, 20, 5, 1)\n",
" self.conv2 = nn.Conv2d(20, 50, 5, 1)\n",
" self.fc1 = nn.Linear(4*4*50, 500)\n",
" self.fc2 = nn.Linear(500, 10)\n",
"\n",
" def forward(self, x):\n",
" x = F.relu(self.conv1(x))\n",
" x = F.max_pool2d(x, 2, 2)\n",
" x = F.relu(self.conv2(x))\n",
" x = F.max_pool2d(x, 2, 2)\n",
" x = x.view(-1, 4*4*50)\n",
" x = F.relu(self.fc1(x))\n",
" x = self.fc2(x)\n",
" return F.log_softmax(x, dim=1)\n",
"\n",
" def train(model, device, train_loader, optimizer, writer):\n",
" model.train()\n",
" for batch_idx, (data, target) in enumerate(train_loader):\n",
" data, target = data.to(device), target.to(device)\n",
" optimizer.zero_grad()\n",
" output = model(data)\n",
" loss = F.nll_loss(output, target)\n",
" loss.backward()\n",
" optimizer.step()\n",
" if batch_idx % 10 == 0:\n",
" print('[{}/{} ({:.0f}%)]\\tLoss: {:.6f}'.format(\n",
" batch_idx * len(data), len(train_loader.dataset),\n",
" 100. * batch_idx / len(train_loader), loss.item()))\n",
" writer.add_scalar('Loss/train', loss.item(), batch_idx)\n",
"\n",
" def test(model, device, test_loader):\n",
" model.eval()\n",
" test_loss = 0\n",
" correct = 0\n",
" with torch.no_grad():\n",
" for data, target in test_loader:\n",
" data, target = data.to(device), target.to(device)\n",
" output = model(data)\n",
" test_loss += F.nll_loss(output, target, reduction='sum').item() # sum up batch loss\n",
" pred = output.argmax(dim=1, keepdim=True) # get the index of the max log-probability\n",
" correct += pred.eq(target.view_as(pred)).sum().item()\n",
"\n",
" test_loss /= len(test_loader.dataset)\n",
"\n",
" print('\\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\\n'.format(\n",
" test_loss, correct, len(test_loader.dataset),\n",
" 100. * correct / len(test_loader.dataset)))\n",
" \n",
" return (100. * correct / len(test_loader.dataset))\n",
"\n",
"\n",
" # Training settings\n",
" use_cuda = torch.cuda.is_available()\n",
"\n",
" torch.manual_seed(1)\n",
"\n",
" device = torch.device(\"cuda\" if use_cuda else \"cpu\")\n",
"\n",
" kwargs = {'num_workers': 1, 'pin_memory': True} if use_cuda else {}\n",
" \n",
" # Set SummaryWriter to point to the local directory containing the tensorboard logs\n",
" writer = SummaryWriter(log_dir=tensorboard.logdir()) \n",
"\n",
" # The same working directory may be used multiple times if running multiple experiments\n",
" # Make sure we only download the dataset once\n",
" if not os.path.exists(os.getcwd() + '/MNIST'):\n",
" #Copy dataset from project to local filesystem\n",
" hdfs.copy_to_local('TourData/mnist/MNIST')\n",
" train_loader = torch.utils.data.DataLoader(\n",
" datasets.MNIST(os.getcwd(), train=True, download=False,\n",
" transform=transforms.Compose([\n",
" transforms.ToTensor(),\n",
" transforms.Normalize((0.1307,), (0.3081,))\n",
" ])),\n",
" batch_size=64, shuffle=True, **kwargs)\n",
" test_loader = torch.utils.data.DataLoader(\n",
" datasets.MNIST(os.getcwd(), train=False, download=False,\n",
" transform=transforms.Compose([\n",
" transforms.ToTensor(),\n",
" transforms.Normalize((0.1307,), (0.3081,))\n",
" ])),\n",
" batch_size=1000, shuffle=True, **kwargs)\n",
"\n",
"\n",
" model = Net().to(device)\n",
" optimizer = optim.SGD(model.parameters(), lr=lr, momentum=momentum)\n",
"\n",
" #Single epoch\n",
" train(model, device, train_loader, optimizer, writer)\n",
" acc = test(model, device, test_loader)\n",
" \n",
" # No need to save model when doing hyperparameter optimization\n",
" # torch.save(model.state_dict(), tensorboard.logdir() + \"mnist_cnn.pt\")\n",
" \n",
" return acc"
]
},
{
"cell_type": "code",
"execution_count": 2,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Generation 0 || average metric: 98.81800000000001, best metric: 98.92, best parameter combination: ['lr=0.1', 'momentum=0.5231567238497797']\n",
"\n",
"Generation 1 || average metric: 98.82000000000001, best metric: 98.92, best parameter combination: ['lr=0.1', 'momentum=0.5231567238497797']\n",
"\n",
"Generation 2 || average metric: 98.82000000000001, best metric: 98.92, best parameter combination: ['lr=0.1', 'momentum=0.5231567238497797']\n",
"\n",
"Generation 3 || average metric: 98.82000000000001, best metric: 98.92, best parameter combination: ['lr=0.1', 'momentum=0.5231567238497797']\n",
"\n",
"Generation 4 || average metric: 98.82000000000001, best metric: 98.92, best parameter combination: ['lr=0.1', 'momentum=0.5231567238497797']\n",
"\n",
"Finished Experiment \n",
"\n",
"('hdfs://10.0.208.8:8020/Projects/demo_deep_learning_admin000/Experiments/application_1573559087487_0009/differential_evolution/run.1', {'lr': '0.1', 'momentum': '0.5231567238497797'})"
]
}
],
"source": [
"from hops import experiment\n",
"\n",
"search_dict = {'lr': [0.1, 0.001], 'momentum': [0.1, 0.9]}\n",
"experiment.differential_evolution(wrapper, search_dict, generations=4, population=5, local_logdir=True, direction='max')"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "PySpark",
"language": "",
"name": "pysparkkernel"
},
"language_info": {
"codemirror_mode": {
"name": "python",
"version": 2
},
"mimetype": "text/x-python",
"name": "pyspark",
"pygments_lexer": "ipython3"
}
},
"nbformat": 4,
"nbformat_minor": 4
}