\n",
"\n",
"\n",
"\n",
"\n",
"## The `hops` python module\n",
"\n",
"`hops` is a helper library for Hops that facilitates development by hiding the complexity of running applications and iteracting with services.\n",
"\n",
"Have a feature request or encountered an issue? Please let us know on github.\n",
"\n",
"### Using the `experiment` module\n",
"\n",
"To be able to run your Machine Learning code in Hopsworks, the code for the whole program needs to be provided and put inside a wrapper function. Everything, from importing libraries to reading data and defining the model and running the program needs to be put inside a wrapper function.\n",
"\n",
"The `experiment` module provides an api to Python programs such as TensorFlow, Keras and PyTorch on a Hopsworks on any number of machines and GPUs.\n",
"\n",
"An Experiment could be a single Python program, which we refer to as an **Experiment**. \n",
"\n",
"Grid search or genetic hyperparameter optimization such as differential evolution which runs several Experiments in parallel, which we refer to as **Parallel Experiment**. \n",
"\n",
"ParameterServerStrategy, CollectiveAllReduceStrategy and MultiworkerMirroredStrategy making multi-machine/multi-gpu training as simple as invoking a function for orchestration. This mode is referred to as **Distributed Training**.\n",
"\n",
"### Using the `tensorboard` module\n",
"The `tensorboard` module allow us to get the log directory for summaries and checkpoints to be written to the TensorBoard we will see in a bit. The only function that we currently need to call is `tensorboard.logdir()`, which returns the path to the TensorBoard log directory. Furthermore, the content of this directory will be put in as a Dataset in your project's Experiments folder.\n",
"\n",
"The directory could in practice be used to store other data that should be accessible after the experiment is finished.\n",
"```python\n",
"# Use this module to get the TensorBoard logdir\n",
"from hops import tensorboard\n",
"tensorboard_logdir = tensorboard.logdir()\n",
"```\n",
"\n",
"### Using the `hdfs` module\n",
"The `hdfs` module provides a method to get the path in HopsFS where your data is stored, namely by calling `hdfs.project_path()`. The path resolves to the root path for your project, which is the view that you see when you click `Data Sets` in HopsWorks. To point where your actual data resides in the project you to append the full path from there to your Dataset. For example if you create a mnist folder in your Resources Dataset, the path to the mnist data would be `hdfs.project_path() + 'Resources/mnist'`\n",
"\n",
"```python\n",
"# Use this module to get the path to your project in HopsFS, then append the path to your Dataset in your project\n",
"from hops import hdfs\n",
"project_path = hdfs.project_path()\n",
"```\n",
"\n",
"```python\n",
"# Downloading the mnist dataset to the current working directory\n",
"from hops import hdfs\n",
"mnist_hdfs_path = hdfs.project_path() + \"Resources/mnist\"\n",
"local_mnist_path = hdfs.copy_to_local(mnist_hdfs_path)\n",
"```\n",
"\n",
"### Documentation\n",
"See the following links to learn more about running experiments in Hopsworks\n",
"\n",
"- Learn more about experiments\n",
" \n",
"- Building End-To-End pipelines\n",
" \n",
"- Give us a star, create an issue or a feature request on Hopsworks github\n",
"\n",
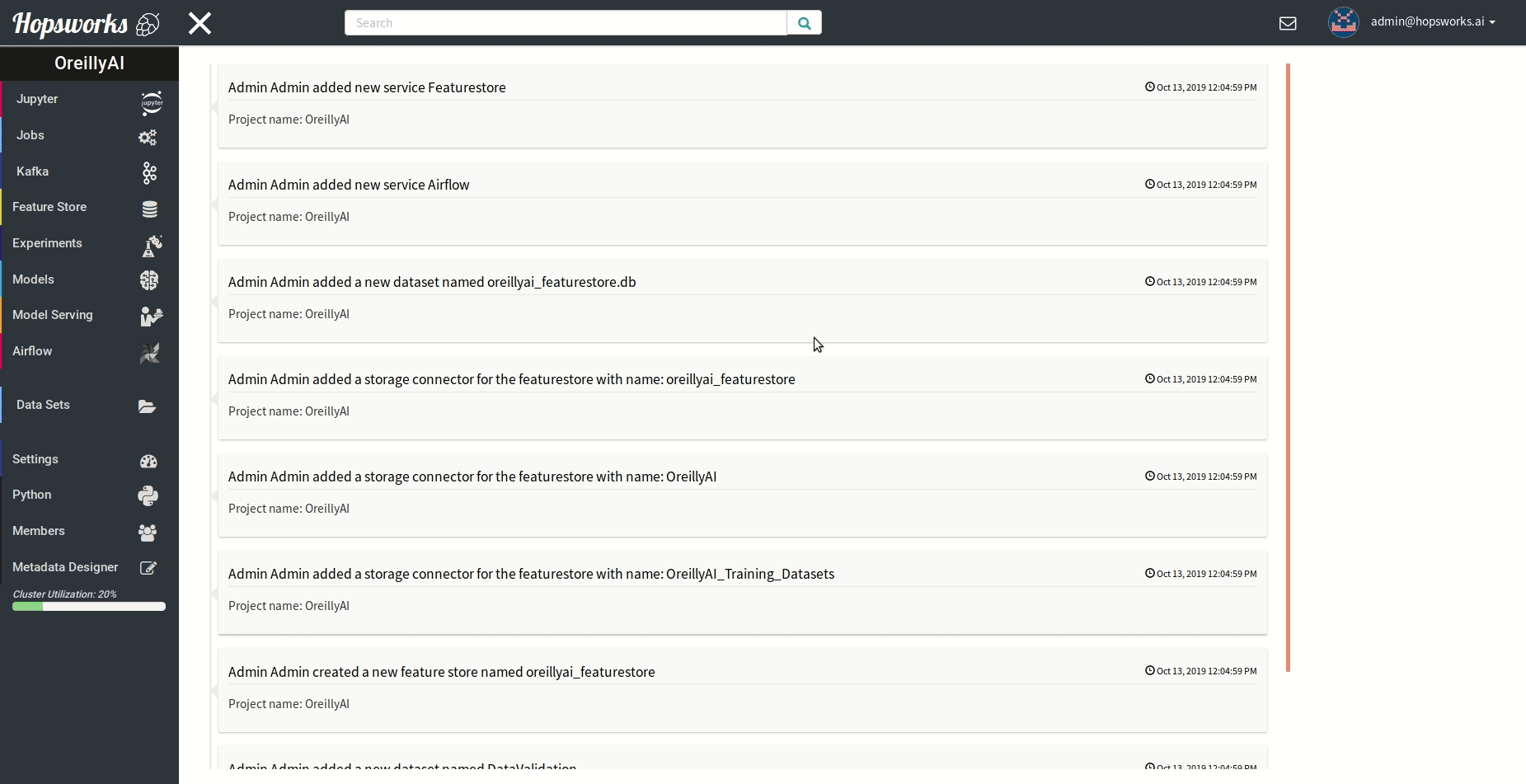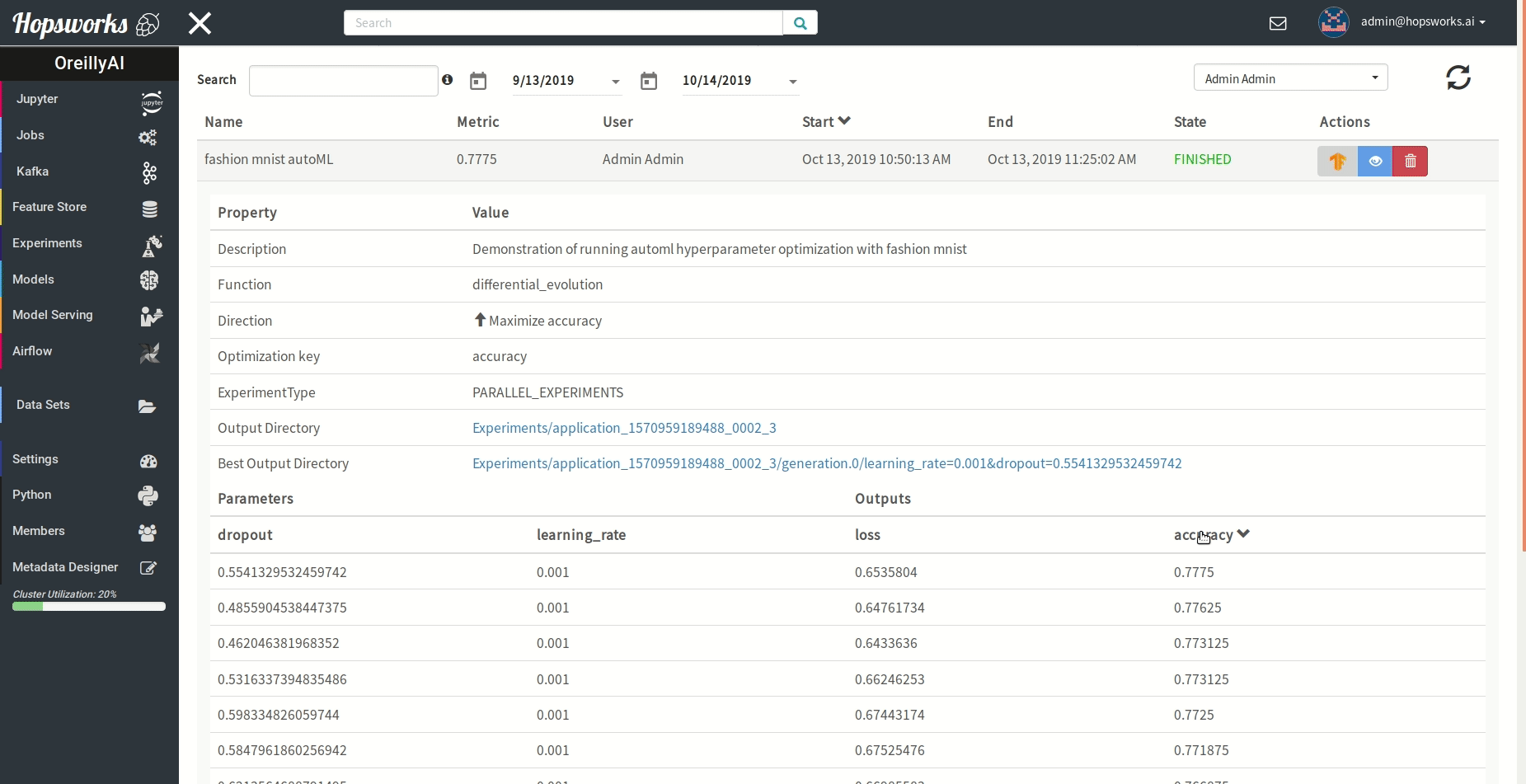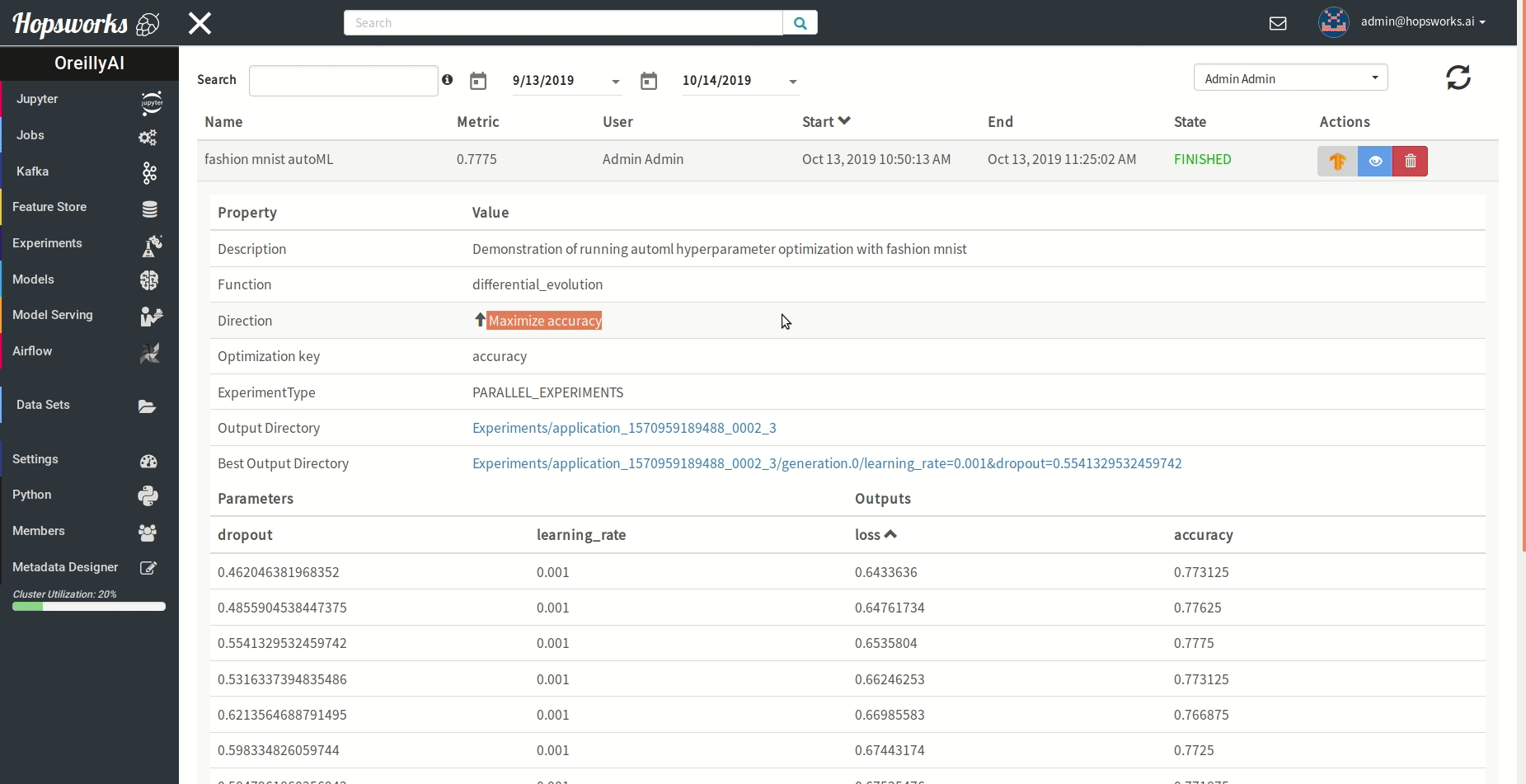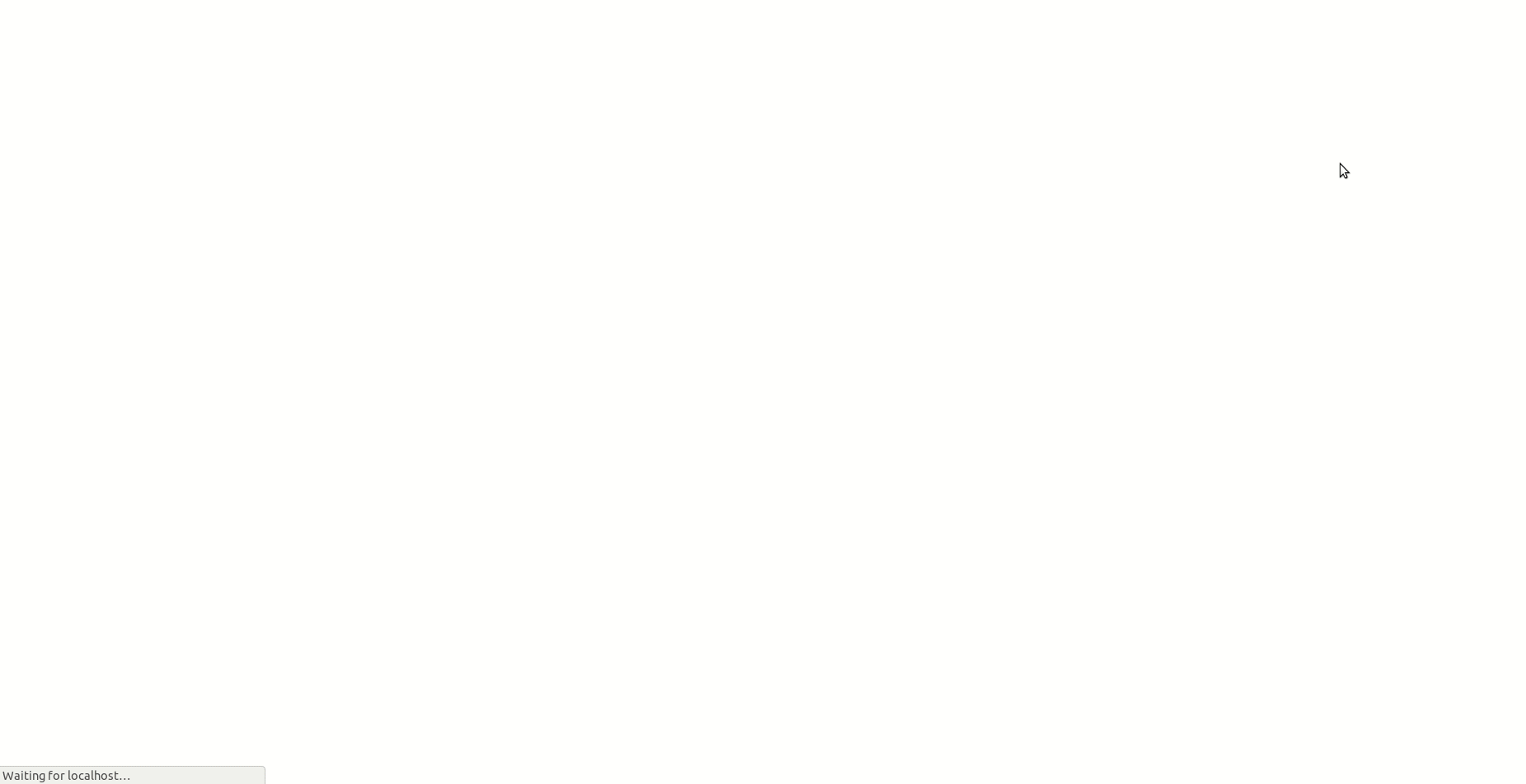
"### Managing experiments\n",
"Experiments service provides a unified view of all the experiments run using the `experiment` module.\n",
" \n",
"As demonstrated in the gif it provides general information about the experiment and the resulting metric. Experiments can be visualized meanwhile or after training in a TensorBoard.\n",
" \n",
" \n",
""
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"def debugger_example():\n",
" # Copyright 2016 The TensorFlow Authors. All Rights Reserved.\n",
" #\n",
" # Licensed under the Apache License, Version 2.0 (the \"License\");\n",
" # you may not use this file except in compliance with the License.\n",
" # You may obtain a copy of the License at\n",
" #\n",
" # http://www.apache.org/licenses/LICENSE-2.0\n",
" #\n",
" # Unless required by applicable law or agreed to in writing, software\n",
" # distributed under the License is distributed on an \"AS IS\" BASIS,\n",
" # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n",
" # See the License for the specific language governing permissions and\n",
" # limitations under the License.\n",
" # ==============================================================================\n",
" \"\"\"Demo of the tfdbg curses CLI: Locating the source of bad numerical values.\n",
"\n",
" The neural network in this demo is larged based on the tutorial at:\n",
" tensorflow/examples/tutorials/mnist/mnist_with_summaries.py\n",
"\n",
" But modifications are made so that problematic numerical values (infs and nans)\n",
" appear in nodes of the graph during training.\n",
" \"\"\"\n",
"\n",
" import argparse\n",
" import sys\n",
" import os\n",
"\n",
" import tensorflow as tf\n",
"\n",
" from tensorflow.examples.tutorials.mnist import input_data\n",
" from tensorflow.python import debug as tf_debug\n",
" \n",
" from hops import tensorboard\n",
"\n",
" IMAGE_SIZE = 28\n",
" HIDDEN_SIZE = 500\n",
" NUM_LABELS = 10\n",
" RAND_SEED = 42\n",
" LEARNING_RATE = 0.025\n",
" STEPS = 10\n",
" \n",
" tensorboard_debug_address = tensorboard.interactive_debugger()\n",
" \n",
" # How you easily get the TensorBoard logdir for summaries\n",
" tensorboard_logdir = tensorboard.logdir()\n",
"\n",
" # Import data\n",
" mnist = input_data.read_data_sets(os.getcwd(),\n",
" one_hot=True,\n",
" fake_data=False)\n",
"\n",
" def feed_dict(train):\n",
" if train:\n",
" xs, ys = mnist.train.images, mnist.train.labels\n",
" else: \n",
" xs, ys = mnist.test.images, mnist.test.labels\n",
" \n",
" return {x: xs, y_: ys}\n",
"\n",
" sess = tf.InteractiveSession()\n",
"\n",
" # Create the MNIST neural network graph.\n",
"\n",
" # Input placeholders.\n",
" with tf.name_scope(\"input\"):\n",
" x = tf.placeholder(\n",
" tf.float32, [None, IMAGE_SIZE * IMAGE_SIZE], name=\"x-input\")\n",
" y_ = tf.placeholder(tf.float32, [None, NUM_LABELS], name=\"y-input\")\n",
"\n",
" def weight_variable(shape):\n",
" \"\"\"Create a weight variable with appropriate initialization.\"\"\"\n",
" initial = tf.truncated_normal(shape, stddev=0.1, seed=RAND_SEED)\n",
" return tf.Variable(initial)\n",
"\n",
" def bias_variable(shape):\n",
" \"\"\"Create a bias variable with appropriate initialization.\"\"\"\n",
" initial = tf.constant(0.1, shape=shape)\n",
" return tf.Variable(initial)\n",
"\n",
" def nn_layer(input_tensor, input_dim, output_dim, layer_name, act=tf.nn.relu):\n",
" \"\"\"Reusable code for making a simple neural net layer.\"\"\"\n",
" # Adding a name scope ensures logical grouping of the layers in the graph.\n",
" with tf.name_scope(layer_name):\n",
" # This Variable will hold the state of the weights for the layer\n",
" with tf.name_scope(\"weights\"):\n",
" weights = weight_variable([input_dim, output_dim])\n",
" with tf.name_scope(\"biases\"):\n",
" biases = bias_variable([output_dim])\n",
" with tf.name_scope(\"Wx_plus_b\"):\n",
" preactivate = tf.matmul(input_tensor, weights) + biases\n",
"\n",
" activations = act(preactivate)\n",
" return activations\n",
"\n",
" hidden = nn_layer(x, IMAGE_SIZE**2, HIDDEN_SIZE, \"hidden\")\n",
" logits = nn_layer(hidden, HIDDEN_SIZE, NUM_LABELS, \"output\", tf.identity)\n",
" y = tf.nn.softmax(logits)\n",
"\n",
" with tf.name_scope(\"cross_entropy\"):\n",
"\n",
" diff = tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=logits)\n",
" with tf.name_scope(\"total\"):\n",
" cross_entropy = tf.reduce_mean(diff)\n",
"\n",
" with tf.name_scope(\"train\"):\n",
" train_step = tf.train.AdamOptimizer(LEARNING_RATE).minimize(\n",
" cross_entropy)\n",
"\n",
" with tf.name_scope(\"accuracy\"):\n",
" with tf.name_scope(\"correct_prediction\"):\n",
" correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))\n",
" with tf.name_scope(\"accuracy\"):\n",
" accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))\n",
"\n",
" sess.run(tf.global_variables_initializer())\n",
" sess = tf_debug.TensorBoardDebugWrapperSession(\n",
" sess, tensorboard_debug_address)\n",
"\n",
" # Add this point, sess is a debug wrapper around the actual Session if\n",
" for i in range(STEPS):\n",
" \n",
" acc = sess.run(accuracy, feed_dict=feed_dict(False))\n",
" print(\"Accuracy at step %d: %s\" % (i, acc))\n",
"\n",
" sess.run(train_step, feed_dict=feed_dict(True))\n",
"\n",
"\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from hops import experiment\n",
"experiment.launch(debugger_example, name='tensorboard debugger', local_logdir=True)"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "PySpark",
"language": "",
"name": "pysparkkernel"
},
"language_info": {
"codemirror_mode": {
"name": "python",
"version": 2
},
"mimetype": "text/x-python",
"name": "pyspark",
"pygments_lexer": "ipython3"
}
},
"nbformat": 4,
"nbformat_minor": 4
}